Step 1 : Consolidate sensitive information in file(s) and ignore from the repo
The first naive thought is just to write all the sensitive information in a file and don’t commit it. List the file in .gitignore so that nobody accidentally commits it.
For example, we can store all API keys/secrets in app/keys.properties:
Basically, you read the sensitive file and get the key value pairs, feed the corresponding API key value you want into the magic function **buildConfigField**. This function is going to create a static field with provided parameters after gradle sync. The auto generated**BuildConfig.java** will look like this.
1 2 3 4
public final class BuildConfig { ... public static final String TMDB_API_KEY = "XXXXYYYYZZZZ"; }
Now you can access this global variable from anywhere in the app. If you are using Retrofit to generate API client code, you can do something like this.
Now, this is awesome. Your sensitive information is consolidated in a single place (keys.properties in this example) and is not going to be easily pushed to any repository by accident. You can pass the file to a new team mate as he/she joins. Your team can probably manage the file in 1Password or a dedicated private repository.
NOTE: Obviously, it is cumbersome and has drawbacks to pass keys.properties to the new team members outside of repository. I will explain the solution in the Step 3.
Step 2: Make CI/CD work with environment variable
With the previous step, we successfully skipped sensitive information to be included in the repository. However, that will cause a problem to the CI/CD system. Remember the build.gradle we wrote above.
The gradle sync on CI/CD server would fail because it cannot find keys.properties, because it was omitted from the repository.
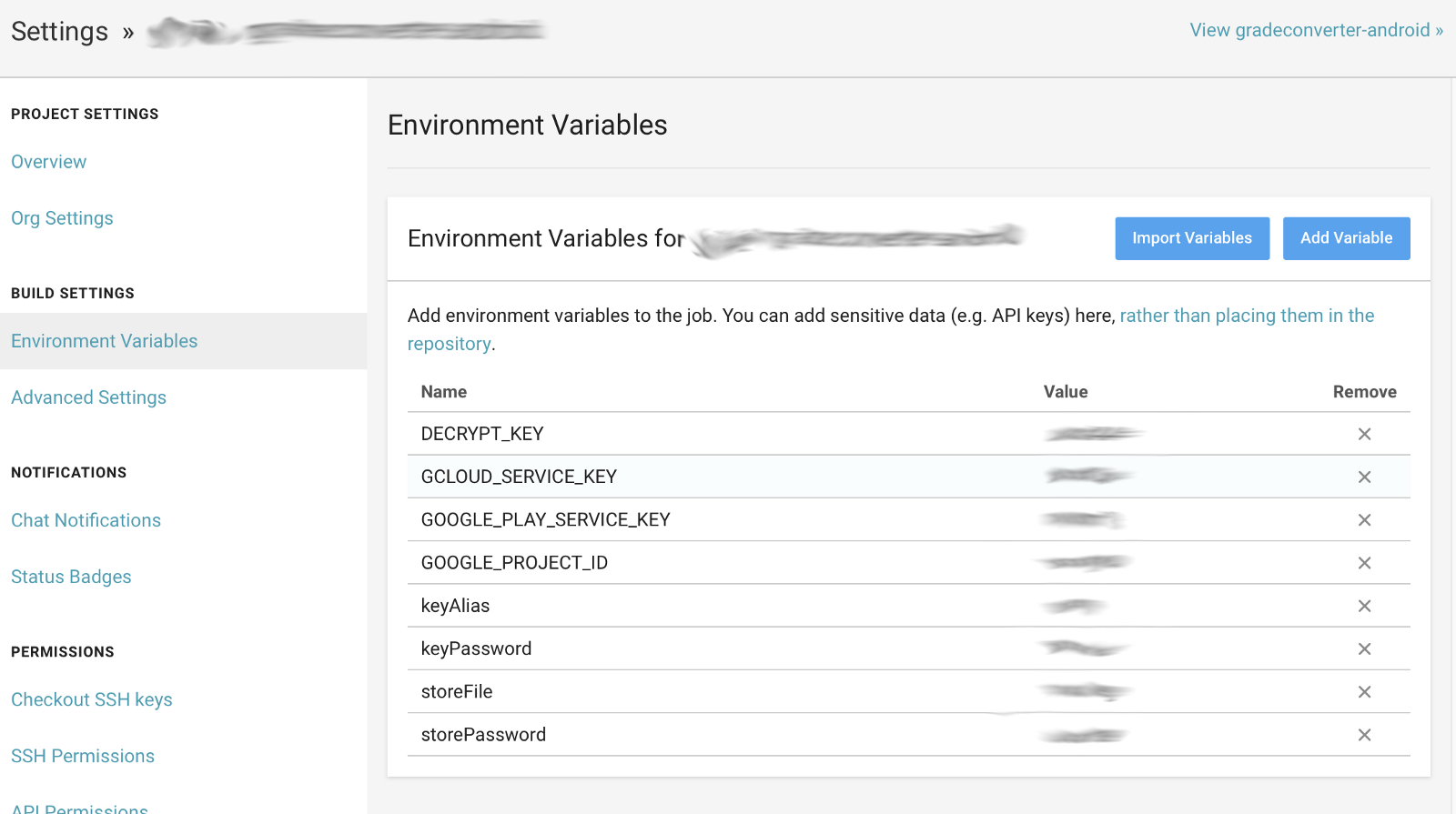
You might have guessed : here comes good old environment variables. Every CI/CD system has an entry for environment variables. This screen is from Circle CI for example.
Environment Variables Screen for Circle CI
You can just “Add Variable” forTMDB_API_KEY in this case.
And of course, we have to modify our gradle script to look at environment variables in addition to the file(s).
1 2 3 4 5 6 7 8 9 10 11 12
def getTmdbApiKey() { def tmdbApiKey = System.getenv("TMDB_API_KEY") if (tmdbApiKey == null || tmdbApiKey.length() == 0) { def keysFile = file("keys.properties") def keysProperties = new Properties() keysProperties.load(new FileInputStream(keysFile)) tmdbApiKey = keysProperties['TMDB_API_KEY'] if (tmdbApiKey == null) { logger.error("You need to either place appropriate keys.properties or set proper environment variables for API key") } } return tmdbApiKey }
Now, in the modified function above, we first look at the environment variable TMDB_API_KEY. If the environment variable is not defined, we will read from the file as before. As long as CI/CD has that environment variable properly set, it can successfully generate a build.
Step 3 : Encrypt the sensitive keys and push to the repository
By consolidating sensitive key information in file(s) and configuring gradle scripts properly, you can set up your Android project to hide sensitive information from the repository.
With this approach, however, we have to have another storage to just store the sensitive information. If we use some password manager (e.g., 1Password), then you cannot manage versions of the sensitive file. You can work this around by setting up a dedicated private repository, but it’s a bit cumbersome that you have to pull/copy the file from a separate repository.
Here comes git-secret. It uses GPG under the hood and allows easy interface for the repository manager to encrypt secret files so that only certain developers are allowed to decrypt those.
Initial Setup
The repository manager needs to put the repository under control of git-secret and specify file(s) to encrypt. This only needs to happen once. Following commands should be executed from the top level directory of the repository.
1 2
% git secret init // You only need to do this once % git secret add app/keys.properties // You only need to do this once per file
Developer passes the public key to the repository manager
The repository manager needs to obtain GPG public key from individual developers. Individual developer can follow this link to create and export GPG public key. One important thing for the developer is that he/she SHOULD NEVER FORGET THE PASSPHRASE HE/SHE SET HERE. It’s quite cumbersome to recover from that situation, and I bet you want to avoid facing unhappy devops or a tech lead.
Repository manager encrypts secret file(s) using the public keys.
On receiving the public key, the repository manager runs the following command.
1
% gpg --import IMPORTED_PUBLIC_KEY.txt
Now, repository managers machine can encrypt any file using developers’ GPG public keys. The repo manager can then type following command to grant access for the developer to the respository.
1
% git secret tell xxx@yyy.com
The Email is the one associated to the imported public key. You can probably check the email via **pgp --list-keys** after doing the import.
Now, you can issue the magic command:
1
% git secret hide
This will create an encrypted file app/keys.properties.secret out of app/keys.properties, using the public keys registered to the machine. The repository manager can then push the encrypted file to the repository.
Any developer can decrypt secret file(s) with a simple command.
1
% git secret reveal
The above command lets you regenerate app/keys.properties out of app/keys.properties.secret as long as the steps above have been successfully completed. 💥💥💥
The initial setup is a little bit involved process, but it becomes very simple after that. Every time a new developer comes in, he/she needs to send the public key to the repository manager, where he/she add the user and re-encrypt the file(s). The new member can then just pull the repository and enter **git secret reveal**. It is much better than searching the file in some other storage, possibly without knowing whether that is the latest version or not.
Summary
I have introduced the 3 steps to share sensitive information without pushing it to the repository. The 3rd step is probably optional at this point. It requires some effort of setting up, and also has some shortcomings like follows:
You always need to run the **git secret hide** command in a machine that has everybody’s public keys.
When the secret file(s) is updated and pushed to the repo, developers should not forget to run **git secret reveal**. Otherwise, you will keep running the app based on old info.
However, the above points are limitations of current toolset and hopefully will get better soon. Overall, the trend is heading to the direction to commit encrypted version of secret files in the same repository. Another tool that fills the same purpose is git-crypt.
First 2 steps, at this moment, is probably something we should follow in every Android project. Once CI systems offer reliable support for git-secret or git-crypt, we may just implement the decryption process on the CI and skip Step2 (getting info through environment variable)
After using Gson for parsing JSON API responses in android I started using the Moshi JSON library created by Square as it targets the android platform, supports using Kotlin language features, is lightweight (with codegen) and has a simpler API.
As a consumer of a restful API with JSON responses it is preferable to handle any issues at the boundary of the data layer in your model rather than have them propagate into the app and have to track them down. Kotlin’s native language features are supported with Moshi to ensure the type safety of a Kotlin class used with adapters to parse JSON responses.
This article demonstrates how this is achieved from setting up Moshi, using it to parse JSON into a simple model object and implementing your own adapter.
Set-up using codegen
Prior to version 1.6 Moshi was implemented using reflection with the kotlin-reflect artifact which at 2.5MB is quite heavyweight for an android app. Since version 1.6 you can also use codegen with the moshi-kotlin-codegen artifact. This is preferred for runtime performance and use of Kotlin language features in the generated adapters. (The only limitation compared with the reflection artifact is that it doesn’t support private and protected fields). In this article I’ll use codegen which requires this gradle configuration:
Consider this JSON and Kotlin data class for a movie:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
{ "vote_count": 2026, "id": 19404, "title": "Example Movie", "image_path": "/example-movie-image.jpg", "overview": "Overview of example movie" } @JsonClass(generateAdapter = true) dataclassMovie ( @Json(name = "vote_count")val voteCount: Int = -1, val id: Int, val title: String, @Json(name = "image_path")val imagePath: String, val overview: String )
There are a couple of things to highlight here. We’ve annotated the class with@JsonClass(generateAdapter = true) which will generate a JsonAdapter to handle serializing/deserializing to and from JSON of the specified type.
The@Json(name = “value”) annotation defines the JSON key name for serialisation and the property to set the value on with deserialization.
This annotation works similarly to *@SerializedName(“some_json_key”)* in Gson and *@JsonProperty("some_json_key")* in Jackson.
To hook it all up and parse the json to the data class you need to create a Moshi object, create the adapter instance and then pass the JSON to the adapter:
1 2 3
val moshi: Moshi = Moshi.Builder().build() val adapter: JsonAdapter<Movie> = moshi.adapter(Movie::class.java) val movie = adapter.fromJson(moviesJson))
Moshi handling of null and absent JSON fields
If the JSON response changes and sets a null field in the JSON then the adapter will fail respecting the non null reference of a val property in the data class and throw a clear exception.
1 2 3 4 5 6 7 8
{ "vote_count": 2026, "id": 19404, "title": "Example Movie", "image_path": "/example-movie-image.jpg", "overview": null } com.squareup.moshi.JsonDataException: Non-null value 'overview' was null at $[0].overview
If the JSON response has an absent field then again the reason for the thrown exception is clear:
Default properties work just as expected setting the voteCount to -1 if it is absent in the consumed JSON. If the property is nullable, however, and null is set in the the JSON then the null value takes precedence. So @Json(name = "vote_count") val voteCount: Int? = -1 will set voteCount to null if “vote_count": null is in the JSON.
Creating your own JSON adapter
There will be times when you don’t want a JSON key to map directly to a Kotlin property and you can create your own custom adapter to change the parsing.
Take a look at the updated JSON and corresponding model where genres the movie belongs to have been introduced referenced by genre id:
{ "vote_count": 2026, "id": 19404, "title": "Example Movie", "genre_ids": [ 35, 18, 10749 ], "overview": "Overview of example movie" } @JsonClass(generateAdapter = true) dataclassMovie ( @Json(name = "vote_count")val voteCount: Int = -1, val id: Int, val title: String, @Json(name = "genre_ids")val genres: List<Genre>, val overview: String ) dataclassGenre(val id: Int, val name: String)
As you haven’t specified how to map the ids to create a genre the parsing fails with com.squareup.moshi.JsonDataException: Expected BEGIN_OBJECT but was NUMBER at path $[0].genre_ids[0] From the model you can see a list of Genre is expected in the JSON but a list of NUMBER is found
To do this mapping you need to create your own adapter and register it when you create the moshi instance:
The mapping is now handled and you can create Genres from the ids in the JSON. You could do this mapping after consuming the JSON by specifying @Json(name = “genre_ids”) val genres: List<Int>, but it’s better to use Moshi to do this when you ingest the content as you will discover any issues sooner.
Sample projects showing full code of the examples with data from The Movie Database using both moshi codegen and moshi reflection with architecture components are available in the repo below.
I hope this article helps you get up-to-speed with Moshi if you are considering using it for your android project. Comments are welcome. Happy parsing!
Before continuing with the rest, let’s first explain what a receiver is in the Kotlin language, because the functions let, also, apply, and run are extension functions that operate on their receiver.
Nowadays, in modern Object Oriented Programming terminology, our code calls a method on an instance of a class. This executes a function (method) in the context of an object (instance of a class), usually referenced by the optional keyword this.
In older Object Oriented Programming parlance (Smalltalk), the function is often referred to as the message, while the instance is referred to as the receiver. The call sends the message to the receiver.
The receiver is the object on which a function is executed and, in Kotlin, this function can be a plain old instance method or it can be an extension function.
1 2 3
val arguments = ... val result = arguments.apply { ... } // 'arguments' is the receiver result.also { ... } // 'result' is the receiver
Now let’s dive into how we can choose the correct one.
Note: The code-snippets are hosted on https://play.kotlinlang.org, which show up as embedded and runnable code in blog posts. You may need to click Show Embed and then accept the data-collection policy by clicking **Y**.
The also function takes a lambda with one parameter and…
Provides its receiver to the lambda’s parameter Inside the lambda, the receiver can be used through the keyword **it**.
Calls the lambda The code in the lambda executes side-effects on the receiver. Side-effects can be logging, rendering on a screen, sending its data to storage or to the network, etc.
Returns its receiver The returned value is the receiver, but now with side-effects applied to it.
Use ‘run’ for transforming objects
1
inline fun <T, R> T.run(lambda: T.() -> R): R
1 2 3 4 5 6 7 8 9 10 11
funmain() { val map = mapOf("key1" to 4, "key2" to 20) val logItem = map.run { val count = size val keys = keys val values = values "Map has $count keys $keys and values $values" } println(logItem) }
1
Map has 2 keys [key1, key2] and values [4, 20]
Uses ‘run’ to transform the Map into a printable String of our liking
The run function takes a lambda-with-receiver and…
Provides its receiver to the lambda’s receiver Inside the lambda, the receiver can be used through the optional keyword **this**.
Calls the lambda and gets the its result of the lambda The code in the lambda calculates a result based on the receiver.
Returns the result of the lambda This allows the function to transform the receiver of type T into a value of type R that was returned by the lambda.
Use ‘let’ for transforming nullable properties
1
inline fun <T, R> T.let(lambda: (T) -> R): R
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classMapper { val mapProperty : Map<String, Int>? = mapOf("key1" to 4, "key2" to 20) funtoLogString() : String { return mapProperty?.let { val count = it.size val keys = it.keys val values = it.values "Map has $count keys $keys and values $values" } ?: "Map is empty" } }
funmain() { println(Mapper().toLogString()) }
1
Map has 2 keys [key1, key2] and values [4, 20]
Uses ‘let’ to transform the nullable property of Mapper into a printable String of our liking
The let function takes a lambda with one parameter and…
Provides its receiver to the lambda’s parameter Inside the lambda, the receiver can be used through the keyword **it**.
Calls the lambda and gets its result The code in the lambda calculates a result based on the receiver.
Returns the result of the lambda This allows the function to transform the receiver of type T into a value of type R that was returned by the lambda.
As we can see, there is no big difference between the usage of run or let.
We should prefer to use let when
The receiver is a nullableproperty of a class. In multi-threaded environments, a nullable property could be set to null just after a null-check but just before actually using it. This means that Kotlin cannot guarantee null-safety even after if (myNullableProperty == null) { ... } is true. In this case, use myNullableProperty**?.let** { ... }, because the it inside the lambda will never be null.
The receiver this inside the lambda of run may get confused with another this from an outer-scope or outer-class. In other words, if our code in the lambda would become unclear or too muddled, we may want to use let.
Use ‘with’ to avoid writing the same receiver over and over again
1
inline fun <T, R> with(receiver: T, block: T.() -> R): R
Use ‘with’ to avoid writing ‘remoteControl.’ over and over again
The with function is like the run function but it doesn’t have a receiver. Instead, it takes a ‘receiver’ as its first parameter and the lambda-with-receiver as its second parameter. The function…
Provides its first parameter to the lambda’s receiver Inside the lambda, the receiver can be used through the optional keyword **this**.
Calls the lambda and get its result We no longer need to write the same receiver over and over againbecause the receiver is represented by the optional keyword this.
Returns the result of the lambda Although the receiver of type T is transformed into a value of type R , the return value of a with function is usually ignored.
Use ‘run’ or ‘with’ for calling a function with multiple receivers
Earlier we discussed the concept of a receiver in Kotlin. An object not only can have one receiver, an object can have two receivers. For a function with two receivers, one receiver is the object for which this instance function is implemented, the other receiver is extended by the function.
Here’s an example where adjustVolume is a function with multiple (two) receivers:
funmain() { val audioSource = object: AudioSource { // Is extended by 'adjustVolume' overrideval volume = 20.0 } val avReceiver = AVReceiver(-4.0) // The context in which 'adjustVolume' will be called val outputVolume1 : Double val outputVolume2 : Double outputVolume1 = avReceiver.run { audioSource.adjustVolume() } with(avReceiver) { outputVolume2 = audioSource.adjustVolume() } println("$outputVolume1 and $outputVolume2") }
1
16.0 and 16.0
In the above example of adjustVolume, this@AVReceiver is the instance-receiver and this@adjustVolume is the extended-receiver for theAudioSource.
The instance-receiver is often called the context. In our example, the extension-function adjustVolume for an AudioSource can be called in the context of an AVReceiver.
We know how to call a function on a single receiver. Just write **receiver**.myFunction(param1, param2) or something similar. But how can we provide not one but two receivers? This is where run and with can help.
Using run or with, we can call a receiver’s extension-function in the contextof another receiver. The context is determined by the receiver of run, or the first parameter of with.
funmain() { val audioSource = object: AudioSource { // Is extended by 'adjustVolume' overrideval volume = 20.0 } val avReceiver = AVReceiver(-4.0) // The context in which 'adjustVolume' will be called val outputVolume1 : Double val outputVolume2 : Double outputVolume1 = avReceiver.run { audioSource.adjustVolume() } with(avReceiver) { outputVolume2 = audioSource.adjustVolume() } println("$outputVolume1 and $outputVolume2")
1
16.0 and 16.0
The ‘adjustVolume’ is called on an AudioSource in the context of an AVReceiver
Quick Recap
The return values and how the receivers are referenced in the lambda
The function apply configures or builds objects
The function also executes side-effects on objects
The function run transforms its receiver into a value of another type
The function let transforms a nullable property of a class into a value of another type
The function with helps you avoid writing the same receiver over and over again
- Bonus Points -
There are few more Standard Library Kotlin functions defined besides the five we talked about just now. Here is a short list of the other ones:
inline fun **TODO**(reason: String = " ... ") : Nothing Todo throws an exception with the provided, but optional, reason. If we forget to implement a piece of code and don’t remove this todo, our app may crash.
inline fun **repeat**(times: Int, action: (Int) -> Unit): Unit Repeat calls the provided action a given number of times. We can write less code using repeat instead of a for loop.
inline fun <T> T.**takeIf**(predicate: (T) -> Boolean) : T? TakeIf returns the receiver if the predicate returns true, otherwise it returns null. It is an alternative to an if (...)expression.
inline fun <T> T.**takeUnless**(predicate: (T) -> Boolean) : T? TakeUnless returns the receiver if the predicate returns false, otherwise it returns null. It is an alternative to an if(**!**...) expression.
If we need to code something like if (long...expression.predicate()), we may need to repeat the long expression again in the then or else clause. Use TakeIf or TakeUnless to avoid this repetition.
In part one, we explored the problems that coroutines are great at solving. As a recap, coroutines are a great solution to two common programming problems:
Long running tasks are tasks that take too long to block the main thread.
Main-safety allows you to ensure that any suspend function can be called from the main thread.
To solve these problems, coroutines build upon regular functions by adding suspend and resume. When all coroutines on a particular thread are suspended, the thread is free to do other work.
However, coroutines by themselves don’t help you keep track of the work that’s being done. It’s perfectly fine to have a large number of coroutines — hundreds or even thousands — and have all of them suspended at the same time. And, while coroutines are cheap, the work they perform is often expensive, like reading files or making network requests.
It’s quite difficult to keep track of one thousand coroutines manually using code. You could try to track all of them and manually ensure they complete or cancel, but code like this is tedious and error prone. If the code is not perfect, it will lose track of a coroutine, which is what I call a work leak.
A work leak is like a memory leak, but worse. It’s a coroutine that’s been lost. In addition to using memory, a work leak can resume itself to use CPU, disk, or even launch a network request.
A leaked coroutine can waste memory, CPU, disk, or even launch a network request that’s not needed.
To help avoid leaking coroutines, Kotlin introduced structured concurrency. Structured concurrency is a combination of language features and best practices that, when followed, help you keep track of all work running in coroutines.
On Android, we can use structured concurrency to do three things:
Cancel work when it is no longer needed.
Keep track of work while it’s running.
Signal errors when a coroutine fails.
Lets dive into each of these and see how structured concurrency helps us make sure we never lose track of a coroutine and leak work.
Cancel work with scopes
In Kotlin, coroutines must run in something called a CoroutineScope. A CoroutineScope keeps track of your coroutines, even coroutines that are suspended. Unlike the Dispatchers we talked about in part one, it doesn’t actually execute your coroutines — it just makes sure you don’t lose track of them.
To ensure that all coroutines are tracked, Kotlin does not allow you to start a new coroutine without a CoroutineScope. You can think of a CoroutineScopeas sort of like lightweight version of an ExecutorService with superpowers. It grants you the ability to start new coroutines which come with all that suspend and resume goodness we explored in part one.
A CoroutineScope keeps track of all your coroutines, and it can cancel all of the coroutines started in it. This fits well with Android development where you want to ensure that you clean up everything that was started by a screen when the user leaves.
A CoroutineScope keeps track of all your coroutines, and it can cancel all of the coroutines started in it.
Starting new coroutines
It’s important to note that you can’t just call a suspend function from anywhere. The suspend and resume mechanism requires that you switch from normal functions to a coroutine.
There are two ways to start coroutines, and they have different uses:
launch builder will start a new coroutine that is “fire and forget” — that means it won’t return the result to the caller.
async builder will start a new coroutine, and it allows you to return a result with a suspend function called await.
In almost all cases, the right answer for how to start a coroutine from a regular function is to use launch. Since the regular function has no way to call await (remember, it can’t call suspend functions directly) it doesn’t make much sense to use async as your main entry to coroutines. We’ll talk later about when it makes sense to use async.
You should instead use a coroutine scope to start a coroutine by calling launch.
1 2 3 4 5 6 7
scope.launch { // This block starts a new coroutine // "in" the scope. // // It can call suspend functions fetchDocs() }
You can think of launch as a bridge that takes your code from regular functions into a coroutines world. Inside of the launch body, you can call suspend functions and create main safety like we covered in the last post.
Launch is a bridge from regular functions into coroutines.
Warning: A big difference between launch and async is how they handle exceptions. async expects that you will eventually call await to get a result (or exception) so it won’t throw exceptions by default. That means if you useasync to start a new coroutine it will silently drop exceptions.
Since launch and async are only available on a CoroutineScope, you know that any coroutine you create will always be tracked by a scope. Kotlin just doesn’t let you create an untracked coroutine, which goes a long way to avoid work leaks.
Start in the ViewModel
So if a CoroutineScope keeps track of all coroutines that are launched in it, and launch creates a new coroutine, where exactly should you call launchand put your scopes? And, when does it make sense to cancel all the coroutines started in a scope?
On Android, it often makes sense to associate a CoroutineScope with a user screen. This lets you avoid leaking coroutines or doing extra work for Activities or Fragments that are no longer relevant to the user. When the user navigates away from the screen, the CoroutineScope associated with the screen can cancel all work.
Structured concurrency guarantees when a scopecancels, all of its coroutinescancel.
When integrating coroutines with Android Architecture Components, you typically want to launch coroutines in the ViewModel. This is a natural place since that’s where most serious work starts — and you won’t have to worry about rotation killing all your coroutines.
To use coroutines in a ViewModel, you can use the viewModelScopeextension property from lifecycle-viewmodel-ktx:2.1.0-alpha04.viewModelScope is on-track to be released in AndroidX Lifecycle (v2.1.0) and is currently in alpha. You can read more about how it works in @manuelvicnt’s blog post. As the library is currently in alpha, there may be bugs, and the APIs could change before the final release. If find any bugs, you can file them here.
Take a look at this example:
1 2 3 4 5 6 7 8
class MyViewModel(): ViewModel() { fun userNeedsDocs() { // Start a new coroutine in a ViewModel viewModelScope.launch { fetchDocs() } } }
viewModelScope will automatically cancel any coroutine that is started by this ViewModel when it is cleared (when the onCleared() callback is called). This is typically the right behavior — if we haven’t fetched the docs, and the user has closed the app, we’re probably just wasting their battery completing the request.
And for more safety, a CoroutineScope will propagate itself. So, if a coroutine you start goes on to start another coroutine, they’ll both end up in the same scope. That means even when libraries that you depend on start a coroutine from your viewModelScope, you’ll have a way to cancel them!
Warning: Coroutines are cancelled cooperatively by throwing a CancellationException when the coroutine is suspended. Exception handlers that catch a top-level exception like Throwable will catch this exception. If you consume the exception in an exception handler, or never suspend, the coroutine will linger in a semi-canceled state.
So, when you need a coroutine to run as long as a ViewModel, use viewModelScope to switch from regular functions to coroutines. Then, since viewModelScope will automatically cancel coroutines for you, it’s totally fine to write an infinite loop here without creating leaks.
1 2 3 4 5 6 7 8 9 10
fun runForever() { // start a new coroutine in the ViewModel viewModelScope.launch { // cancelled when the ViewModel is cleared while(true) { delay(1_000) // do something every second } } }
By using viewModelScope you’re able to ensure that all work, even this infinite loop, is cancelled when it is no longer needed.
Keep track of work
Launching one coroutine is good — and for a lot of code that’s really all you’ll ever need to do. Launch a coroutine, make a network request, and write the result to the database.
Sometimes, though, you need a bit more complexity. Say you wanted to do two network requests simultaneously (or at the same time) in a coroutine — to do that you’ll need to start more coroutines!
To make more coroutines, any suspend functions can start more coroutines by using another builder called coroutineScope or its cousin supervisorScope. This API is, honestly, a bit confusing. The coroutineScope builder and a CoroutineScope are different things despite only having one character difference in their name.
Launching new coroutines everywhere is one way to create potential work leaks. The caller may not know about the new coroutines, and if it doesn’t how could it keep track of the work?
To fix this, structured concurrency helps us out. Namely, it provides a guarantee that when a suspend function returns, all of its work is done.
Structured concurrency guarantees that when a suspend function returns, all of its work is done.
Here’s an example of using coroutineScope to fetch two documents:
In this example, two documents are fetched from the network simultaneously. The first one is fetched in a coroutine started with launch which is “fire and forget” — that means it won’t return the result to the caller.
The second document is fetched with async, so the document can be returned to the caller. This example is a little weird, since typically you would use async for both documents — but I wanted to show that you can mix and match launch and async depending on what you need.
coroutineScope and supervisorScope let you safely launch coroutines from suspend functions.
Note, though, that this code never explicitly waits for either of the new coroutines! It seems like fetchTwoDocs will return while the coroutines are running!
To make structured concurrency and avoid work leaks, we want to ensure that when a suspend function like fetchTwoDocs returns, all of its work is done. That means both of the coroutines it launches must complete before fetchTwoDocs returns.
Kotlin ensures that the work does not leak from fetchTwoDocs with the coroutineScope builder. The coroutineScope builder will suspend itself until all coroutines started inside of it are complete. Because of this, there’s no way to return from fetchTwoDocs until all coroutines started in the coroutineScope builder are complete.
Lots and lots of work
Now that we’ve explored keeping track of one and two coroutines, it’s time to go all-in and try to keep track of one thousand coroutines!
Take a look at the following animation:
Animation showing how a coroutineScope can keep track of one thousand coroutines.
This example shows making one thousand network request simultaneously. This is not recommend in real Android code — your app will use lots of resources.
In this code, we launch one thousand coroutines with launch inside a coroutineScope builder. You can see how things get wired up. Since we’re in a suspend function, some code somewhere must have used a CoroutineScopeto create a coroutine. We don’t know anything about that CoroutineScope, it could be a viewModelScope or some other CoroutineScope defined somewhere else. No matter what calling scope it is, the coroutineScopebuilder will use it as the parent to the new scope it creates.
Then, inside the coroutineScope block, launch will start coroutines “in” the new scope. As the coroutines started by launch complete, the new scope will keep track of them. Finally, once all of the coroutines started inside the coroutineScope are complete, loadLots is free to return.
Note: the parent-child relationship between scopes and coroutines is created using Job objects. But you can often think of the relationship between coroutines and scopes without diving into that level.
coroutineScope and supervisorScope will wait for child coroutines to complete.
There’s a lot going on here under the hood — but what’s important is that using coroutineScope or supervisorScope you can launch a coroutine safely from any suspend function. Even though it will start a new coroutine, you won’t accidentally leak work because you’ll always suspend the caller until the new coroutine completes.
What’s really cool is coroutineScope will create a child scope. So if the parent scope gets cancelled, it will pass the cancellation down to all the new coroutines. If the caller was the viewModelScope, all one thousand coroutines would be automatically cancelled when the user navigated away from the screen. Pretty neat!
Before we move on to errors, it’s worth taking a moment to talk about supervisorScope vs. coroutineScope. The main difference is that a coroutineScope will cancel whenever any of its children fail. So, if one network request fails, all of the other requests are cancelled immediately. If instead you want to continue the other requests even when one fails, you can use a supervisorScope. A supervisorScope won’t cancel other children when one of them fails.
Signal errors when a coroutine fails
In coroutines, errors are signaled by throwing exceptions, just like regular functions. Exceptions from a suspend function will be re-thrown to the caller by resume. Just like with regular functions, you’re not limited to try/catch to handle errors and you can build abstractions to perform error handling with other styles if you prefer.
However, there are situations where errors can get lost in coroutines.
1 2 3 4 5 6 7 8
val unrelatedScope = MainScope() // example of a lost error suspend fun lostError() { // async without structured concurrency unrelatedScope.async { throw InAsyncNoOneCanHearYou("except") } }
Note this code is declaring an unrelated coroutine scope that will launch a new coroutine without structured concurrency. Remember at the beginning I said that structured concurrency is a combination of types and programming practices, and introducing unrelated coroutine scopes in suspend functions is not following the programming practices of structured concurrency.
The error is lost in this code because async assumes that you will eventually call await where it will rethrow the exception. However, if you never do call await, the exception will be stored forever waiting patiently waiting to be raised.
Structured concurrency guarantees that when a coroutine errors, its caller or scope is notified.
If you do use structured concurrency for the above code, the error will correctly be thrown to the caller.
Since the coroutineScope will wait for all children to complete, it can also get notified when they fail. If a coroutine started by coroutineScope throws an exception, coroutineScope can throw it to the caller. Since we’re using coroutineScope instead of supervisorScope, it would also immediately cancel all other children when the exception is thrown.
Using structured concurrency
In this post, I introduced structured concurrency and showed how it makes our code fit well with Android ViewModel to avoid work leaks.
I also talked about how it makes suspend functions easier to reason about. Both by ensuring they complete work before they return, as well as ensuring they signal errors by surfacing exceptions.
If instead we used unstructured concurrency, it would be easy for coroutines to accidentally leak work that the caller didn’t know about. The work would not be cancellable, and it would not be guaranteed that exceptions would be rethrown. This would make our code more surprising, and possibly create obscure bugs.
You can create unstructured concurrency by introducing a new unrelated CoroutineScope (note the capital C), or by using a global scope called GlobalScope, but you should only consider unstructured concurrency in rare cases when you need the coroutine to live longer than the calling scope. It’s a good idea to then add structure yourself to ensure you keep track of the unstructured coroutines, handle errors, and have a good cancellation story.
Structured concurrency does take some getting used to if you have experience with unstructured concurrency. The structure and guarantees do it make it safer and easier to interact with suspend functions. It’s a good idea to work with structured concurrency as much as possible, because it helps make code easier to read and much less surprising.
At the start of this post I listed three things that structured concurrency solves for us
Cancel work when it is no longer needed.
Keep track of work while it’s running.
Signal errors when a coroutine fails.
To accomplish this structured concurrency gives us some guarantees about our code. Here are the guarantees of structured concurrency.
When a scopecancels, all of its coroutinescancel.
When a suspend funreturns, all of its work is done.
When a coroutineerrors, its caller or scope is notified.
Put together, the guarantees of structured concurrency make our code safer, easier to reason about, and allow us to avoid leaking work!
Kotlin coroutines introduce a new style of concurrency that can be used on Android to simplify async code. While they’re new to Kotlin in 1.3, the concept of coroutines has been around since the dawn of programming languages. The first language to explore using coroutines was Simula in 1967.
In the last few years, coroutines have grown in popularity and are now included in many popular programming languages such as Javascript, C#, Python, Ruby, and Go to name a few. Kotlin coroutines are based on established concepts that have been used to build large applications.
On Android, coroutines are a great solution to two problems:
Long running tasks are tasks that take too long to block the main thread.
Main-safety allows you to ensure that any suspend function can be called from the main thread.
Let’s dive in to each to see how coroutines can help us structure code in a cleaner way!
Long running tasks
Fetching a webpage or interacting with an API both involve making a network request. Similarly, reading from a database or loading an image from disk involve reading a file. These sorts of things are what I call long running tasks — tasks that take far too long for your app to stop and wait for them!
It can be hard to understand how fast a modern phone executes code compared to a network request. On a Pixel 2, a single CPU cycle takes just under 0.0000004 seconds, a number that’s pretty hard to grasp in human terms. However, if you think of a network request as one blink of the eye, around 400 milliseconds (0.4 seconds), it’s easier to understand how fast the CPU operates. In one blink of an eye, or a somewhat slow network request, the CPU can execute over one million cycles!
On Android, every app has a main thread that is in charge of handling UI (like drawing views) and coordinating user interactions. If there is too much work happening on this thread, the app appears to hang or slow down, leading to an undesirable user experience. Any long running task should be done without blocking the main thread, so your app doesn’t display what’s called “jank,” like frozen animations, or respond slowly to touch events.
In order to perform a network request off the main thread, a common pattern is callbacks. Callbacks provide a handle to a library that it can use to call back into your code at some future time. With callbacks, fetching developer.android.com might look like this:
1 2 3 4 5 6 7
class ViewModel: ViewModel() { fun fetchDocs() { get("developer.android.com") { result -> show(result) } } }
Even though get is called from the main thread, it will use another thread to perform the network request. Then, once the result is available from the network, the callback will be called on the main thread. This is a great way to handle long running tasks, and libraries like Retrofit can help you make network requests without blocking the main thread.
Using coroutines for long running tasks
Coroutines are a way to simplify the code used to manage long running tasks like fetchDocs. To explore how coroutines make the code for long running tasks simpler, let’s rewrite the callback example above to use coroutines.
1 2 3 4 5 6 7 8 9
// Dispatchers.Main suspend fun fetchDocs() { // Dispatchers.IO val result = get("developer.android.com") // Dispatchers.Main show(result) } // look at this in the next section suspend fun get(url: String) = withContext(Dispatchers.IO){/*...*/}
Doesn’t this code block the main thread? How does it return a result from get without waiting for the network request and blocking? It turns out coroutines provide a way for Kotlin to execute this code and never block the main thread.
Coroutines build upon regular functions by adding two new operations. In addition to invoke (or call) and return, coroutines add suspend and resume.
suspend — pause the execution of the current coroutine, saving all local variables
resume — continue a suspended coroutine from the place it was paused
This functionality is added by Kotlin by the suspend keyword on the function. You can only call suspend functions from other suspend functions, or by using a coroutine builder like launch to start a new coroutine.
Suspend and resume work together to replace callbacks.
In the example above, get will suspend the coroutine before it starts the network request. The function get will still be responsible for running the network request off the main thread. Then, when the network request completes, instead of calling a callback to notify the main thread, it can simply resume the coroutine it suspended.
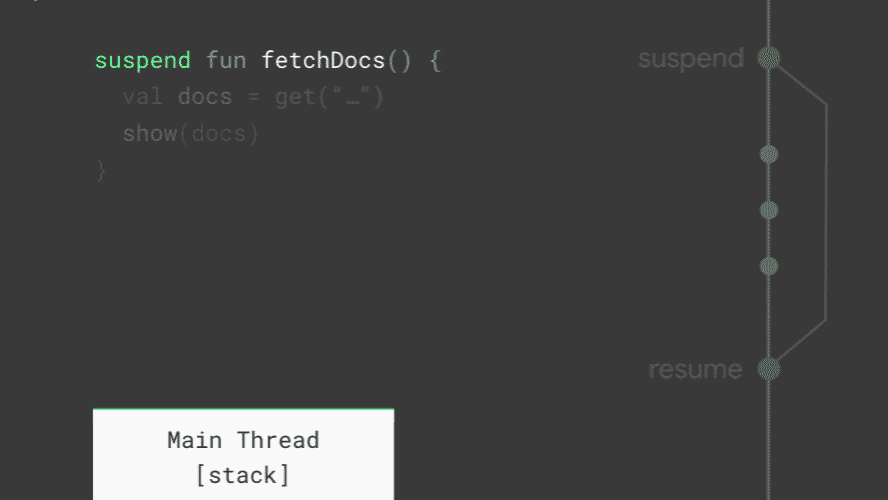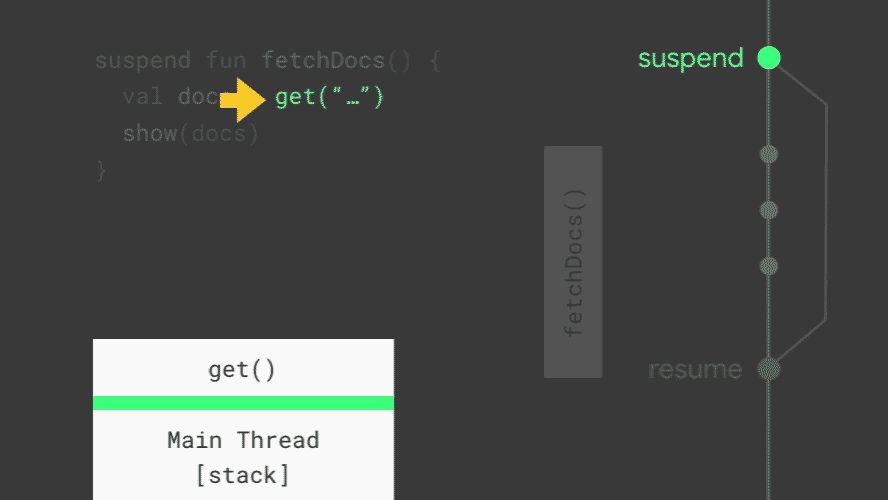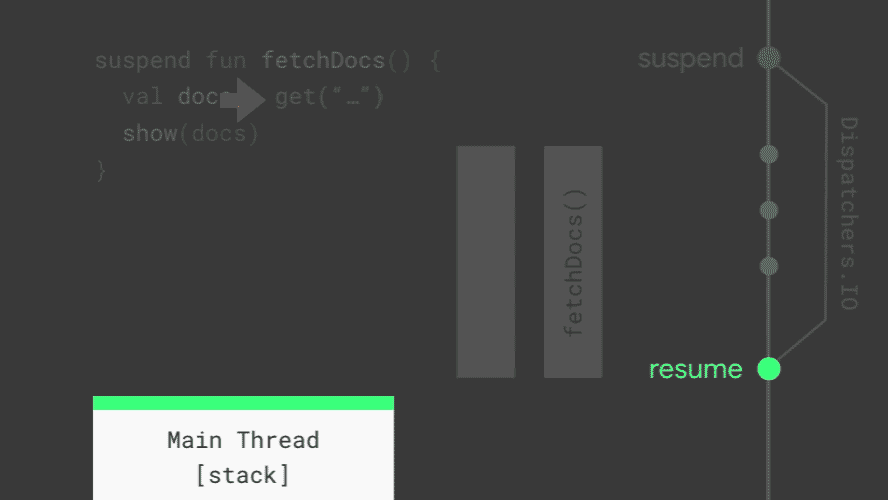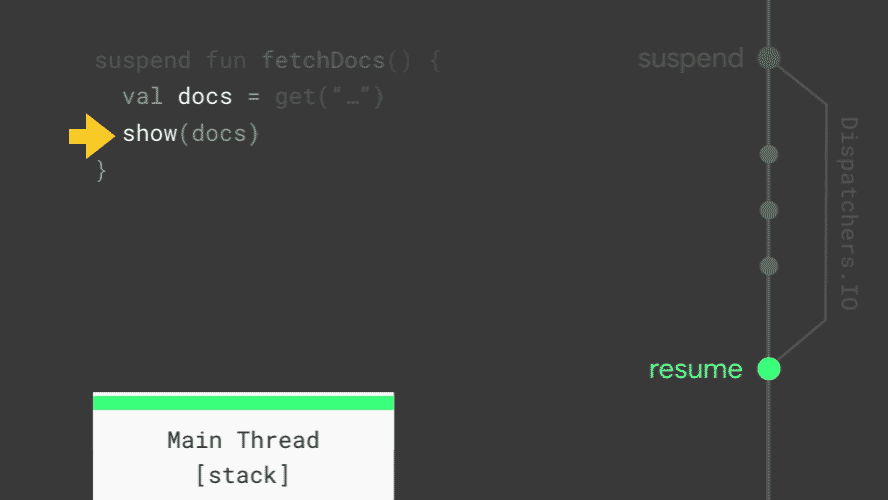
Animation showing how Kotlin implements suspend and resume to replace callbacks.
Looking at how fetchDocs executes, you can see how suspend works. Whenever a coroutine is suspended, the current stack frame (the place that Kotlin uses to keep track of which function is running and its variables) is copied and saved for later. When it resumes, the stack frame is copied back from where it was saved and starts running again. In the middle of the animation — when all of the coroutines on the main thread are suspended, the main thread is free to update the screen and handle user events. Together, suspend and resume replace callbacks. Pretty neat!
When all of the coroutines on the main thread are suspended, the main thread is free to do other work.
Even though we wrote straightforward sequential code that looks exactly like a blocking network request, coroutines will run our code exactly how we want and avoid blocking the main thread!
Next, let’s take a look into how to use coroutines for main-safety and explore dispatchers.
Main-safety with coroutines
In Kotlin coroutines, well written suspend functions are always safe to call from the main thread. No matter what they do, they should always allow any thread to call them.
But, there’s a lot of things we do in our Android apps that are too slow to happen on the main thread. Network requests, parsing JSON, reading or writing from the database, or even just iterating over large lists. Any of these have the potential to run slowly enough to cause user visible “jank” and should run off the main thread.
Using suspend doesn’t tell Kotlin to run a function on a background thread. It’s worth saying clearly and often that coroutines will run on the main thread. In fact, it’s a really good idea to use Dispatchers.Main.immediatewhen launching a coroutine in response to a UI event — that way, if you don’t end up doing a long running task that requires main-safety, the result can be available in the very next frame for the user.
Coroutines will run on the main thread, and suspend does not mean background.
To make a function that does work that’s too slow for the main thread main-safe, you can tell Kotlin coroutines to perform work on either the Default or IO dispatcher. In Kotlin, all coroutines must run in a dispatcher — even when they’re running on the main thread. Coroutines can suspend themselves, and the dispatcher is the thing that knows how to resume them.
To specify where the coroutines should run, Kotlin provides three Dispatchersyou can use for thread dispatch.
+-----------------------------------+ | Dispatchers.Main | +-----------------------------------+ | Main thread on Android, interact | | with the UI and perform light | | work | +-----------------------------------+ | - Calling suspend functions | | - Call UI functions | | - Updating LiveData | +-----------------------------------+
+-----------------------------------+ | Dispatchers.IO | +-----------------------------------+ | Optimized for disk and network IO | | off the main thread | +-----------------------------------+ | - Database* | | - Reading/writing files | | - Networking** | +-----------------------------------+
+-----------------------------------+ | Dispatchers.Default | +-----------------------------------+ | Optimized for CPU intensive work | | off the main thread | +-----------------------------------+ | - Sorting a list | | - Parsing JSON | | - DiffUtils | +-----------------------------------+
*** Networking libraries such as* RetrofitandVolleymanage their own threads and do not require explicit main-safety in your code when used with Kotlin coroutines.
To continue with the example above, let’s use the dispatchers to define the get function. Inside the body of get you call withContext(Dispatchers.IO)to create a block that will run on the IO dispatcher. Any code you put inside that block will always execute on the IO dispatcher. Since withContext is itself a suspend function, it will work using coroutines to provide main safety.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Dispatchers.Main suspend fun fetchDocs() { // Dispatchers.Main val result = get("developer.android.com") // Dispatchers.Main show(result) } // Dispatchers.Main suspend fun get(url: String) = // Dispatchers.IO withContext(Dispatchers.IO) { // Dispatchers.IO /* perform blocking network IO here */ } // Dispatchers.Main
With coroutines you can do thread dispatch with fine-grained control. Because withContext lets you control what thread any line of code executes on without introducing a callback to return the result, you can apply it to very small functions like reading from your database or performing a network request. So a good practice is to use withContext to make sure every function is safe to be called on any Dispatcher including Main — that way the caller never has to think about what thread will be needed to execute the function.
In this example, fetchDocs is executing on the main thread, but can safely call get which performs a network request in the background. Because coroutines support suspend and resume, the coroutine on the main thread will be resumed with the result as soon as the withContext block is complete.
Well written suspend functions are always safe to call from the main thread (or main-safe).
It’s a really good idea to make every suspend function main-safe. If it does anything that touches the disk, network, or even just uses too much CPU, use withContext to make it safe to call from the main thread. This is the pattern that coroutines based libraries like Retrofit and Room follow. If you follow this style throughout your codebase your code will be much simpler and avoid mixing threading concerns with application logic. When followed consistently, coroutines are free to launch on the main thread and make network or database requests with simple code while guaranteeing users won’t see “jank.”
Performance of withContext
withContext is as fast as callbacks or RxJava for providing main safety. It’s even possible to optimize withContext calls beyond what’s possible with callbacks in some situations. If a function will make 10 calls to a database, you can tell Kotlin to switch once in an outer withContext around all 10 calls. Then, even though the database library will call withContext repeatedly, it will stay on the same dispatcher and follow a fast-path. In addition, switching between Dispatchers.Default and Dispatchers.IO is optimized to avoid thread switches whenever possible.
What’s next
In this post we explored what problems coroutines are great at solving. Coroutines are a really old concept in programming languages that have become popular recently due to their ability to make code that interacts with the network simpler.
On Android, you can use them to solve two really common problems:
Simplifying the code for long running tasks such as reading from the network, disk, or even parsing a large JSON result.
Performing precise main-safety to ensure that you never accidentally block the main thread without making code difficult to read and write.
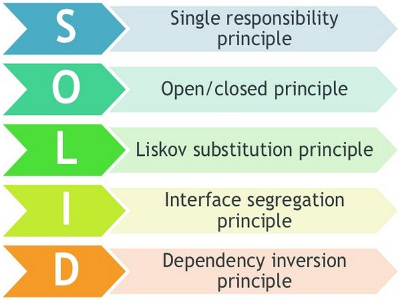
Single Responsibility Principle : It is defined as,A class should have one, and only one, reason to change.
Open-Closed Principle: Software entities (classes, modules, functions, etc…) should be open for extension, but closed for modification Liskov Substitution Principle. — Child classes should never break the parent class’ type definitions.
Liskov Substitution Principle : Child classes should never break the parent class’ type definitions.
Interface Segregation Principle : The interface-segregation principle (ISP) states that no client should be forced to depend on methods it does not use.
Dependency Inversion Principle : High-level modules should not depend on low-level modules. Both should depend on abstractions.Also Abstractions should not depend upon details. Details should depend upon abstractions.
Google introduced Android architecture components which are basically a collection of libraries that facilitate robust design, testable, and maintainable apps. It includes convenient and less error-prone handling of LifeCycle and prevents memory leaks.
Although these components are easy to use with exhaustive documentation, using them inappropriately leads to several issues which could be difficult to debug.
Problem
One such issue our team came across was observing LiveData from ViewModel in Fragment. Let’s say we have two Fragments: FragmentA (which is currently loaded) & FragmentB which user can navigate to. FragmentA is observing data from ViewModel via LiveData.
When
The user navigates to FragmentB, FragmentA gets replaced by FragmentB and the transaction is added to backstack.
After some actions on FragmentB user presses the back button and returns to FragmentA
Then
LiveData observer in FragmentA triggered twice for single emit.
Following is the code Snippet:
1 2 3 4 5 6 7 8 9 10 11 12
@Override public void onActivityCreated(@Nullable Bundle savedInstanceState) { super.onActivityCreated(savedInstanceState); final ProductListViewModel viewModel = ViewModelProviders.of(getActivity()).get(ProductListViewModel.class); viewModel.getProducts().observe(this, new Observer<List<ProductEntity>>() { @Override public void onChanged(List<ProductEntity> productEntities) { //Do something } }); }
If the user navigates to FragmentB again and presses back to visit FragmetnA, the LiveData observer was triggered thrice and it conti01nued to increase
Debugging Approach
The initial thought was somehow(due to Fragment going though lifecycle) ViewModel was triggering LiveData multiple data on the same Observer. We added the following log to ensure this is the case:
1 2 3 4 5 6 7 8 9 10 11 12 13
@Override public void onActivityCreated(@Nullable Bundle savedInstanceState) { super.onActivityCreated(savedInstanceState); final ProductListViewModel viewModel = ViewModelProviders.of(getActivity()).get(ProductListViewModel.class); viewModel.getProducts().observe(this, new Observer<List<ProductEntity>>() { @Override public void onChanged(List<ProductEntity> productEntities) { Log.d("TEST", "[onChanged]: " + hashCode()); //Do something } }); }
After closely observing the hashCode() we discovered that same LiveData was observed twice and whenever value for LiveData was set multiple Observer instances onChanged() were called. This is because the observers were not getting removed when**FragmentA**was getting replaced.
One quick fix we did was to removeObservers() before observing again as follows:
1 2 3 4 5 6 7 8
viewModel.getProducts().removeObservers(this); viewModel.getProducts().observe(this, new Observer<List<ProductEntity>>() { @Override public void onChanged(List<ProductEntity> productEntities) { Log.d("TEST", "[onChanged]: " + hashCode()); //Do something } });
Since its more of a workaround and would be difficult to maintain(each Observe requires removeObservers), I tried to find a proper fix.
In order to do that I had to understand:
Fragment Lifecycle
How LiveData observers are removed
Why onActivityCreated for observing LiveData?
Fragment Lifecycle
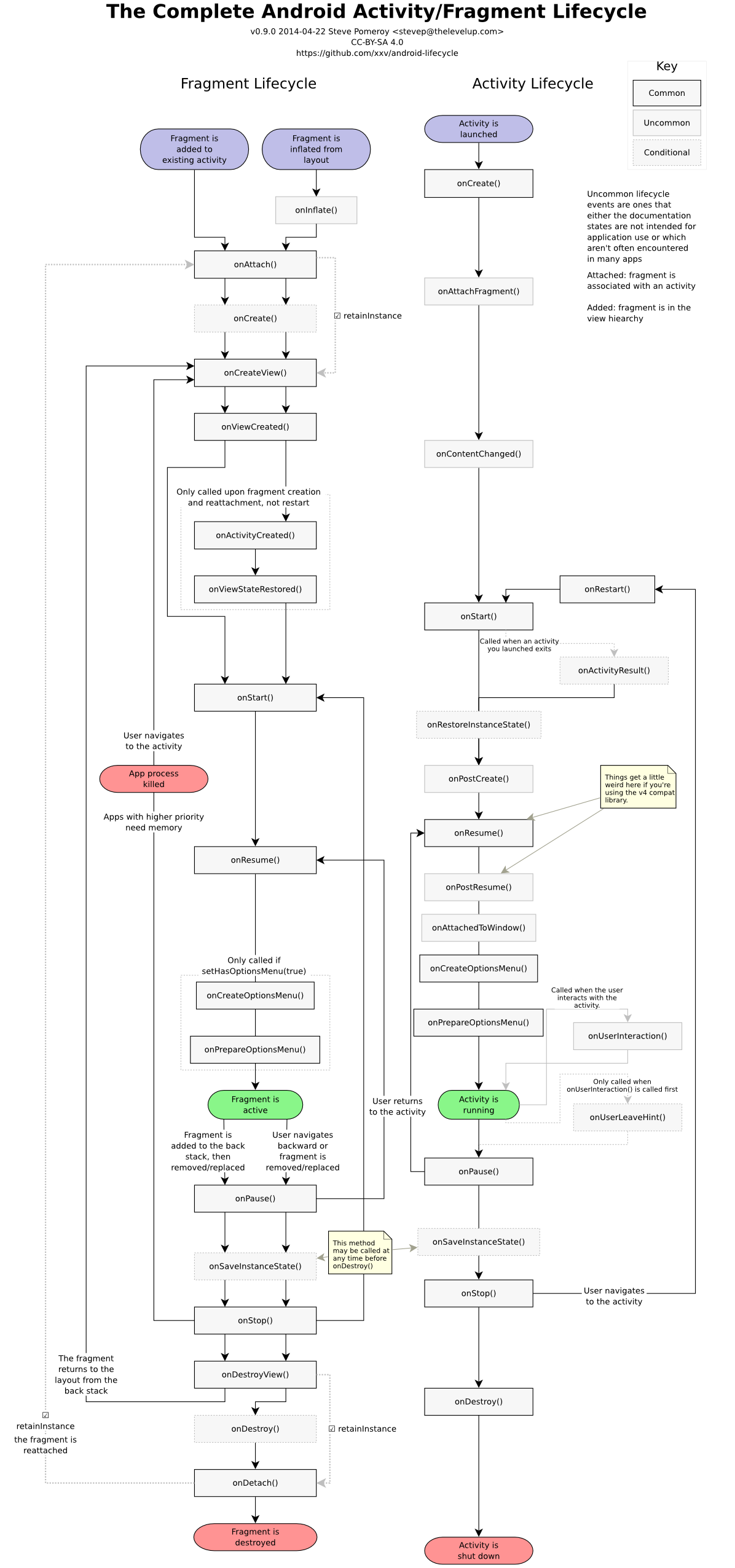
After searching a bit I came across the following diagram which gave a better understanding of Fragment Lifecycle:
Further researching on Fragment I found there are two distinct lifecycles associated with fragment:
You can register an observer paired with an object that implements the LifecycleOwner interface**. This relationship allows the observer to be removed when the state of the corresponding** **Lifecycle**object changes to**DESTROYED**. This is especially useful for activities and fragments because they can safely observe LiveData objects and not worry about leaks—activities and fragments are instantly unsubscribed when their lifecycles are destroyed.
Solution
The lifecycle of Fragment when FragmentA is replaced by FragmentB and the transaction is added to backstack, the state of FragmentA lifecycle is onDestroyView .
When the user presses back on FragmentB , FragmentA goes through onCreateView() → onViewCreated → onActivityCreated
Since FragmentA is never destroyed, the previous Observer is never removed. As a result, each time onActivityCreated was called, a new Observer was registered with the previous one still around. This caused onChanged() called multiple times.
One proper solution is to use getViewLifeCycleOwner() as LifeCycleOwer while observing LiveData inside onActivityCreated as follows:
1 2 3 4 5 6
viewModel.getMainTab().observe(getViewLifecycleOwner(), new Observer<Integer>() { @Override public void onChanged(@Nullable Integer integer) { //Do something } });
Note:
The first method where it is safe to access the view lifecycle is onCreateView(LayoutInflater, ViewGroup, Bundle) under the condition that you must return a non-null view (an IllegalStateException will be thrown if you access the view lifecycle but don’t return a non-null view).
But why not observe in onCreate instead of onActivityCreated?
Generally, LiveData delivers updates only when data changes, and only to active observers. An exception to this behavior is that observers also receive an update when they change from an inactive to an active state. Furthermore, if the observer changes from inactive to active a second time, it only receives an update if the value has changed since the last time it became active.
If we observe in onCreateand Fragment’s view is recreated (visible → backstack → comes back), we have to update the values from ViewModel manually. This is because LiveData will not call the observer since it had already delivered the last result to that observer.
Conclusion
Based on my research:
UsergetViewLifecycleOwner() when you want to observe for LiveData inside onActivityCreated.
If you want to manually update the views and values when Fragment is recreated, observe the LiveData in onCreate()