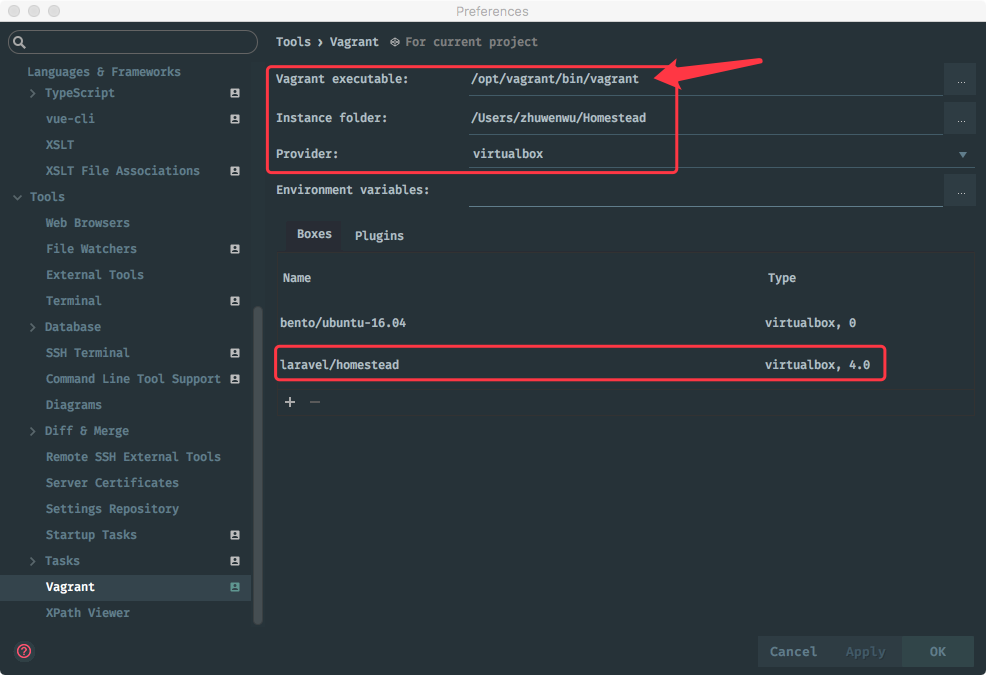
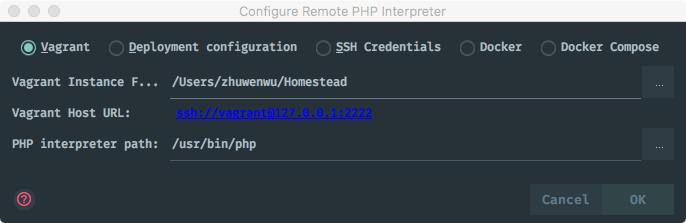
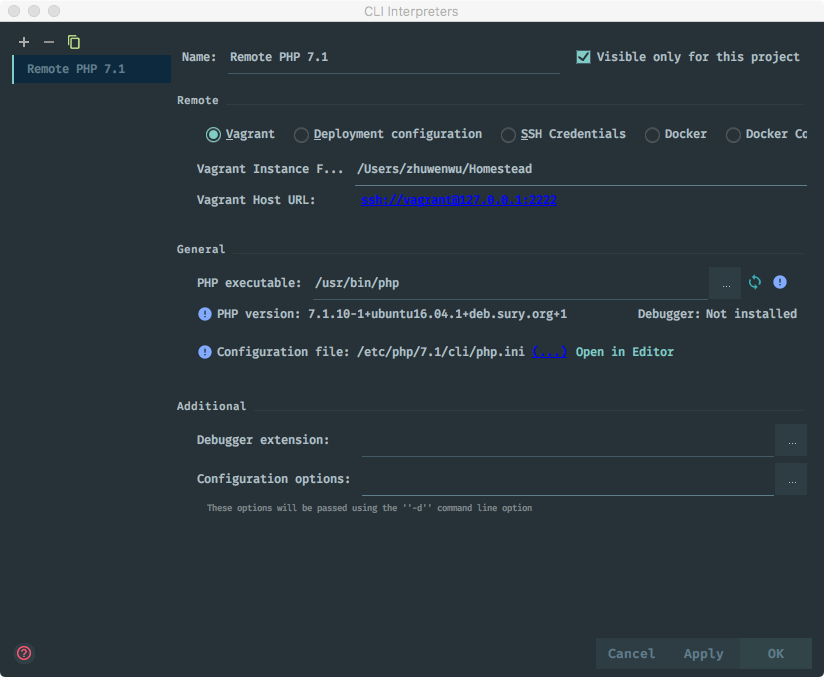
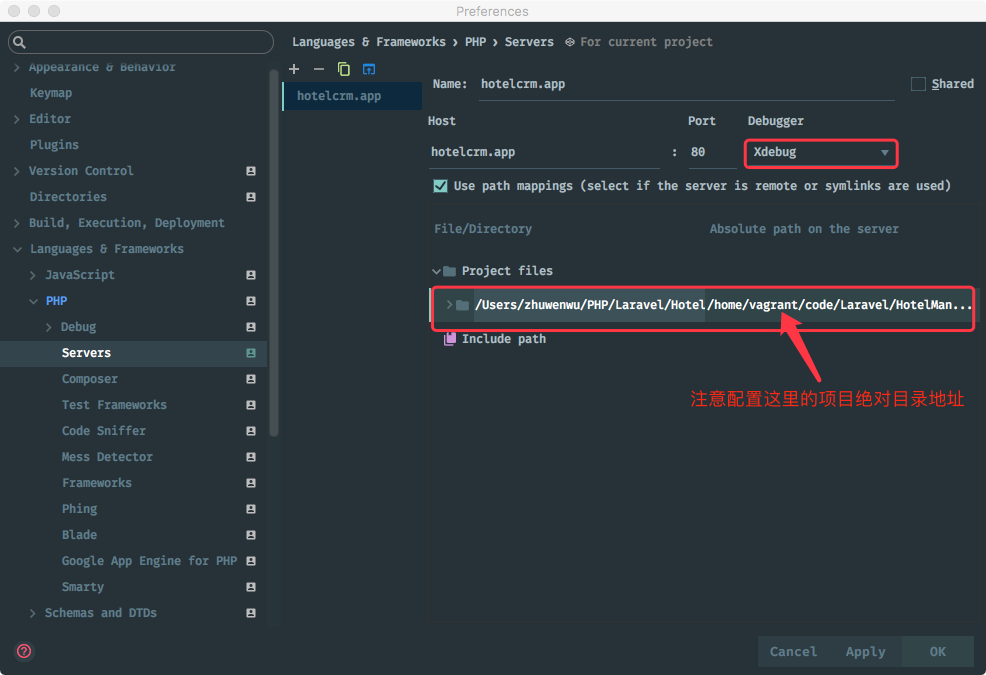
Whenever you develop a Laravel-based application that makes it into production you’ll probably provide some kind of API. Either for internal usage or for the customer to consume. However you most likely want to install some kind of rate limiting mechanism to make sure nobody is overusing your API and thus risking to take down your hosting infrastructure.
A well-known mechanism to prevent APIs from being overloaded with requests (kind of DoS) is a rate limiting. You’ll define a maximum number of requests in a given amount of time and when a client hits that maximum your web server will answer with HTTP 429 Too Many Requests. This indicates the client that there is some kind of cooldown time it needs to wait until further requests will be processed.
Rate Limiting Middleware
Laravel provides a convenient throttle middleware that provides that kind of rate limiting. It even supports different limits based upon a model so you can limit the amount of requests based upon a dynamic parameter.
1 2 3 4 5 6 7 8 9 10 11 12
<?php
// Allow up to 60 requests in 1 minute for that route (= 1 req/s) Route::get('api/v1/user', 'Api\UserController@index')->middleware('throttle:60,1');
// Allow up to 60 requests in 60 minutes for that route (= 1 req/m) Route::post('api/v1/user', 'Api\UserController@store')->middleware('throttle:60,60');
// Rate Limiting for a whole group of routes Route::group(['middleware' => 'throttle:60,1'], function () { // [...] });
Figure 1 — Rate Limiting using Laravel’s “throttle” middleware
This is a pretty cool default functionality. However it comes with a downside you will experience in production: The request stillhits your Laravel application before being denied due to an exceeded limit which means the request still generates load on your web-server.
Of course the impact isn’t as high as it normally would be but in fact the web-server needs to boot up the Laravel framework and the request will pass any middleware that is processed before the throttle middleware itself. This alone could cause some database queries to be executed before the check for the exceeded rate limit even happens.
Finally the request causes impact on your cache server (e.g. Redis). Laravel’s rate limiting middleware stores the client’s IP address alongside with the amount of requests in a given time period and performs a check on every request.
Load Balancer Rate Limiting
A technique I often use when bringing Laravel-based applications into production is a combination of Laravel Middleware Rate Limiting alongside with another rate limiting at the load balancer.
A load balancer is a piece of software that usually sits in front of your web-server stack. The traffic goes from the left to the right until it hits your Laravel application.
Figure 2 — Position of the Load Balancer in the Web-Server Stack
It should be desirable to kill unwanted requests as early as possible in that chain of processing to reduce load in the backend. One of the most used load balancers is HAProxy. Although the website looks like it’s software from the 90s, it’s battle-tested and under very active development. At the time of writing this article HAProxy has reached stable version 2.1 and is “cloud ready” for usage with modern technologies like Kubernetes.
HAProxy is mainly a Layer 7 HTTP Load Balancer (however it also supports some more protocols, which is pretty awesome). That means that it can handle SSL offloading, can look into the user’s request and decide a few key things upon the request details:
First of all it can decide which backend to use for the incoming request which means you could split up your application into two different Laravel applications: One for the frontend and another one for the backend.
It can restrict some URIs to a given IP range or require basic authentication for it. That way I’m able to protect the Laravel Horizon Dashboard in production — it’s only accessible from a specific VPN IP range for additional security.
It can split your user’s request between several backend web-servers which means you are able to scale your deployment. You no longer need to get bigger and bigger machines, you can just add some. And you can remove them if no longer needed (e.g. after a huge sale event, when running a web shop).
However this article will focus on the configuration of rate limiting within HAProxy for the sake of performance and stability of your web-server deployment.
Configuration of HAProxy
Before diving right into the configuration of the rate limiting itself it’s important to configure some basic limitations of HAProxy. You may want to configure a maximum amount of parallel connections that load balancer is allowed to handle at one time.
1 2 3 4 5
backend laravel timeout queue 10s server app-1 10.10.100.101:8080 check maxconn 30 server app-2 10.10.100.102:8080 check maxconn 30 server app-3 10.10.100.103:8080 check maxconn 30
Figure 3 — Max Connection Settings for HAProxy
When there are more than 90 (3 times 30 connections) concurrent connections HAProxy will put those requests in a queue and will forward them once the active connection count drops below 30 again. Usually this happens within milliseconds, so your users will barely notice under normal circumstances. The queue will be flushed after 10 seconds and the client receives an HTTP 503 Service Unavailable which means HAProxy couldn’t elect a backend server to serve the request to the user.
One would ask why you should limit those connections to the backend server. The idea behind this procedure is that it’s better to serve some HTTP errors to some clients than bury your web backend under such a heavy workload your application becomes inoperable. It’s a kind of a protection for your infrastructure.
HAProxy Rate Limiting
To integrate rate limiting functionalities into HAProxy you need to configure a so called stick table within your frontend configuration block. That table works kind of like the Laravel throttle middleware under the hood. It stores a definable value as dictionary key and some counters that belong to that key.
To recognize a user we will use its requesting IP address as dictionary key. And the value we are interested in is the amount of HTTP connection the client establishes.
1 2 3 4 5 6
frontend app bind :80 stick-table type ipv6 size 100k expire 30s store http_req_rate(10s) http-request track-sc0 src http-request deny deny_status 429 if { sc_http_req_rate(0) gt 20 } default_backend laravel
Figure 4 — Establish Rate Limiting within HAProxy
The first two lines of that configuration example are plain and basic frontend definitions in HAProxy. You create a new frontend (something that receives a user’s request) and bind it to port 80 which is the default HTTP port.
In Line 3 you create a stick-table that stores IP addresses as “dictionary key”, has a maximum size of 100k, thats values expire after 30 seconds and that stores the request rate of the latest 10 seconds for each client. The reason why we are using ipv6 as table type is that the default ip type is not able to store IPv6 addresses due to a limitation of the key length. Although the type suggests that the table can only store IPv6 addresses this is not the case; it can easily store both, so don’t worry.
Afterwards we initialize a so called sticky counter (sc) to count the incoming HTTP requests of each user and deny the request with a HTTP 429 Too Many Requests if the HTTP request rate exceeds 20 requests for the given amount of time we defined in Line 3 (in our case this are seconds).
HAProxy will automatically take care of the table and purge old entries. So after some time the clients will be able to connect to the server again.
Downsides
However there are some downsides you should consider when performing rate limiting with HAProxy. The Laravel Throttle Middleware has some neat features for usability.
Figure 5 — X-RateLimit headers of the Laravel Throttle Middleware
As you can see Laravel will automatically add some additional headers to its response when a request got rate-limited. You can see the hard limit of requests (5 in the example) and the remaining amount of requests you can perform before getting a HTTP 429 from the server. Furthermore it provides a counter and a unix timestamp that shows you when you are allowed to perform new requests after a rate limit hit.
You won’t get those headers with the provided HAProxy configuration above. Therefore I personally decided to use the load balancer rate limiting technique alongside with Laravel’s rate limiting middleware. You easily can configure much higher limits within your load balancer than at your Laravel application and you still get some kind of protection against flooding your application.
For example you could set up the Laravel throttle middleware to prevent more requests than 60 per minute so the user gets one request per second. Then you could configure HAProxy to limit the requests when there are more than 120 requests per minute. So if your user is using your API correctly and honors the rate limiting headers he won’t ever hit your load balancer rate limit. But if the user just ignores the headers and continues flooding your application with requests although they get denied by your Laravel middleware he’ll run into your load balancer rate limiting at some point.
By doing this you can efficiently prevent your infrastructure from being flooded with requests.
Conclusion
Laravel provides a convenient default middleware to throttle requests using the cache backend you set up for your application.
In production it may be a problem that your user’s requests still hit your web-server backend although the user is already rate-limited.
Rate limiting via Laravel Middleware costs more than rate limiting at the edge of your web stack (at the load balancer).
HAProxy provides a convenient way to achieve rate limiting using stick-tables and some easy deny rules at the frontend.
It’s better to show some users a HTTP error that burying your infrastructure under heavy load (no matters whether it’s a DoS-attack or just a high amount of legit traffic).
In the future I’ll publish more articles about production-specific experiences with Laravel I made in the past. I hope you can get some takeaways for your own projects.
Hosting is fun and there are many ways to fine-tune your application very individually. One-Click-Hosting solutions may suite for many projects, but when it comes to performance and security you may prefer a tailored solution.
If you have worked with them, you would agree that database design though it seems easier, is a lot trickier in practice. SQL databases believe in structure, that is why it’s called structured query language.
On the other side of the horizon, we have the NoSQL databases, also called schema-less databases that encourage flexibility. In schema-less databases, there is no imposed structural restriction, only data to be saved.
At this moment, you are probably asking yourself why would you want to use JSON when MySQL has been catering to a wide variety of database needs even before it introduced a JSON data type.
The answer lies in the use-cases where you would probably use a make-shift approach.
Let me explain with an example.
Suppose you are building a web application where you have to save a user’s configuration/preferences in the database.
Generally, you can create a separate database table with the id, user_id, key, and value fields or save it as a formatted string that you can parse at runtime.
However, this works well for a small number of users. If you have about a thousand users and five configuration keys, you are looking at a table with five thousand records that addresses a very small feature of your application.
Or if you are taking the formatted string route, extraneous code that only compounds your server load.
Using a JSON data type field to save a user’s configuration in such a scenario can spare you a database table’s space and bring down the number of records, which were being saved separately, to be the same as the number of users.
And you get the added benefit of not having to write any JSON parsing code, the ORM or the language runtime takes care of it.
Before we dive into using all the cool JSON stuff in MySQL, we are going to need a sample database to play with.
So, let’s get our database schema out of the way first.
We are going to consider the use case of an online store that houses multiple brands and a variety of electronics.
Since different electronics have different attributes(compare a Macbook with a Vacuumn Cleaner) that buyers are interested in, typically the Entity–attribute–value model (EAV) pattern is used.
However, since we now have the option to use a JSON data type, we are going to drop EAV.
For a start, our database will be named e_store and has three tables only named, brands, categories, and products respectively.
Our brands and categories tables will be pretty similar, each having an id and a name field.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CREATE DATABASE IF NOTEXISTS `e_store` DEFAULTCHARACTERSET utf8 DEFAULTCOLLATE utf8_general_ci;
Our table definition specifies foreign key constraints for the brand_id and category_id fields, specifying that they reference the brands and categories table respectively. We have also specified that the referenced rows should not be allowed to delete and if updated, the changes should reflect in the references as well.
The attributes field’s column type has been declared to be JSON which is the native data type now available in MySQL. This allows us to use the various JSON related constructs in MySQL on our attributes field.
Here is an entity relationship diagram of our created database.
Our database design is not the best in terms of efficiency and accuracy. There is no price column in the products table and we could do with putting a product into multiple categories. However, the purpose of this tutorial is not to teach database design but rather how to model objects of different nature in a single table using MySQL’s JSON features.
Instead of laying out the JSON object yourself, you can also use the built-in JSON_OBJECT function.
The JSON_OBJECT function accepts a list of key/value pairs in the form JSON_OBJECT(key1, value1, key2, value2, ... key(n), value(n)) and returns a JSON object.
Notice the JSON_ARRAY function which returns a JSON array when passed a set of values.
If you specify a single key multiple times, only the first key/value pair will be retained. This is called normalizing the JSON in MySQL’s terms. Also, as part of normalization, the object keys are sorted and the extra white-space between key/value pairs is removed.
Another function that we can use to create JSON objects is the JSON_MERGE function.
The JSON_MERGE function takes multiple JSON objects and produces a single, aggregate object.
There is a lot happening in these insert statements and it can get a bit confusing. However, it is pretty simple.
We are only passing objects to the JSON_MERGE function. Some of them have been constructed using the JSON_OBJECT function we saw previously whereas others have been passed as valid JSON strings.
In case of the JSON_MERGE function, if a key is repeated multiple times, it’s value is retained as an array in the output.
We can confirm all our queries were run successfully using the JSON_TYPE function which gives us the field value type.
1 2
/* output: OBJECT */ SELECT JSON_TYPE(attributes) FROM `e_store`.`products`;
Read
Right, we have a few products in our database to work with.
For typical MySQL values that are not of type JSON, a where clause is pretty straight-forward. Just specify the column, an operator, and the values you need to work with.
Heuristically, when working with JSON columns, this does not work.
1 2 3 4 5 6 7
/* It's not that simple */ SELECT * FROM `e_store`.`products` WHERE attributes ='{"ports": {"usb": 3, "hdmi": 1}, "screen": "50 inch", "speakers": {"left": "10 watt", "right": "10 watt"}, "resolution": "2048 x 1152 pixels"}';
When you wish to narrow down rows using a JSON field, you should be familiar with the concept of a path expression.
The most simplest definition of a path expression(think JQuery selectors) is it’s used to specify which parts of the JSON document to work with.
The second piece of the puzzle is the JSON_EXTRACT function which accepts a path expression to navigate through JSON.
Let us say we are interested in the range of televisions that have atleast a single USB and HDMI port.
1 2 3 4 5 6 7 8
SELECT * FROM `e_store`.`products` WHERE `category_id` =1 AND JSON_EXTRACT(`attributes` , '$.ports.usb') >0 AND JSON_EXTRACT(`attributes` , '$.ports.hdmi') >0;
The first argument to the JSON_EXTRACT function is the JSON to apply the path expression to which is the attributes column. The $ symbol tokenizes the object to work with. The $.ports.usb and $.ports.hdmi path expressions translate to “take the usb key under ports” and “take the hdmi key under ports” respectively.
Once we have extracted the keys we are interested in, it is pretty simple to use the MySQL operators such as > on them.
Also, the JSON_EXTRACT function has the alias -> that you can use to make your queries more readable.
Revising our previous query.
1 2 3 4 5 6 7 8
SELECT * FROM `e_store`.`products` WHERE `category_id` =1 AND `attributes` ->'$.ports.usb'>0 AND `attributes` ->'$.ports.hdmi'>0;
Update
In order to update JSON values, we are going to use the JSON_INSERT, JSON_REPLACE, and JSON_SET functions. These functions also require a path expression to specify which parts of the JSON object to modify.
The output of these functions is a valid JSON object with the changes applied.
Let us modify all mobilephones to have a chipset property as well.
1 2 3 4 5 6 7 8
UPDATE `e_store`.`products` SET `attributes` = JSON_INSERT( `attributes` , '$.chipset' , 'Qualcomm' ) WHERE `category_id` =2;
The $.chipset path expression identifies the position of the chipset property to be at the root of the object.
Let us update the chipset property to be more descriptive using the JSON_REPLACE function.
1 2 3 4 5 6 7 8
UPDATE `e_store`.`products` SET `attributes` = JSON_REPLACE( `attributes` , '$.chipset' , 'Qualcomm Snapdragon' ) WHERE `category_id` =2;
Easy peasy!
Lastly, we have the JSON_SET function which we will use to specify our televisions are pretty colorful.
1 2 3 4 5 6 7 8
UPDATE `e_store`.`products` SET `attributes` = JSON_SET( `attributes` , '$.body_color' , 'red' ) WHERE `category_id` =1;
All of these functions seem identical but there is a difference in the way they behave.
The JSON_INSERT function will only add the property to the object if it does not exists already.
The JSON_REPLACE function substitutes the property only if it is found.
The JSON_SET function will add the property if it is not found else replace it.
Delete
There are two parts to deleting that we will look at.
The first is to delete a certain key/value from your JSON columns whereas the second is to delete rows using a JSON column.
Let us say we are no longer providing the mount_type information for cameras and wish to remove it for all cameras.
We will do it using the JSON_REMOVE function which returns the updated JSON after removing the specified key based on the path expression.
1 2 3 4
UPDATE `e_store`.`products` SET `attributes` = JSON_REMOVE(`attributes` , '$.mount_type') WHERE `category_id` =3;
For the second case, we also do not provide mobilephones anymore that have the Jellybean version of the Android OS.
1 2 3
DELETEFROM `e_store`.`products` WHERE `category_id` =2 AND JSON_EXTRACT(`attributes` , '$.os') LIKE'%Jellybean%';
As stated previously, working with a specific attribute requires the use of the JSON_EXTRACT function so in order to apply the LIKE operator, we have first extracted the os property of mobilephones(with the help of category_id) and deleted all records that contain the string Jellybean.
The old days of directly working with a database are way behind us.
These days, frameworks insulate developers from lower-level operations and it almost feels alien for a framework fanatic not to be able to translate his/her database knowledge into an object relational mapper.
For the purpose of not leaving such developers heartbroken and wondering about their existence and purpose in the universe, we are going to look at how to go about the business of JSON columns in the Laravel framework.
We will only be focusing on the parts that overlap with our subject matter which deals with JSON columns. An in-depth tutorial on the Laravel framework is beyond the scope of this piece.
Pay attention to the $table->json('attributes'); statement in the migration.
Just like creating any other table field using the appropriate data type named method, we have created a JSON column using the json method with the name attributes.
Also, this only works for database engines that support the JSON data type.
Engines, such as older versions of MySQL will not be able to carry out these migrations.
// Each product has a brand publicfunctionbrand(){ return$this->belongsTo('Brand'); }
// Each product has a category publicfunctioncategory(){ return$this->belongsTo('Category'); } }
Again, our Product model needs a special mention.
The $casts array which has the key attributes set to array makes sure whenever a product is fetched from the database, it’s attributes JSON is converted to an associated array.
We will see later in the tutorial how this facilitates us to update records from our controller actions.
Speaking of the admin panel, the parameters to create a product maybe coming in through different routes since we have a number of product categories. You may also have different views to create, edit, show, and delete a product.
For example, a form to add a camera requires different input fields than a form to add a mobilephone so they warrant separate views.
Moreover, once you have the user input data, you will most probabaly run it through a request validator, separate for the camera, and the mobilephone each.
The final step would be to create the product through Eloquent.
We will be focusing on the camera resource for the rest of this tutorial. Other products can be addressed using the code produced in a similar manner.
Assuming we are saving a camera and the form fields are named as the respective camera attributes, here is the controller action.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// creates product in database // using form fields publicfunctionstore(Request $request){ // create object and set properties $camera = new\App\Product(); $camera->name = $request->name; $camera->brand_id = $request->brand_id; $camera->category_id = $request->category_id; $camera->attributes = json_encode([ 'processor' => $request->processor, 'sensor_type' => $request->sensor_type, 'monitor_type' => $request->monitor_type, 'scanning_system' => $request->scanning_system, ]); // save to database $camera->save(); // show the created camera returnview('product.camera.show', ['camera' => $camera]); }
Fetching Products
Recall the $casts array we declared earlier in the Product model. It will help us read and edit a product by treating attributes as an associative array.
1 2 3 4 5 6
// fetches a single product // from database publicfunctionshow($id){ $camera = \App\Product::find($id); returnview('product.camera.show', ['camera' => $camera]); }
Your view would use the $camera variable in the following manner.
As shown in the previous section, you can easily fetch a product and pass it to the view, which in this case would be the edit view.
You can use the product variable to pre-populate form fields on the edit page.
Updating the product based on the user input will be pretty similar to the store action we saw earlier, only that instead of creating a new product, you will fetch it first from the database before updating it.
Searching Based on JSON Attributes
The last piece of the puzzle that remains to discuss is querying JSON columns using the Eloquent ORM.
If you have a search page that allows cameras to be searched based on their specifications provided by the user, you can do so with the following code.
We have barely scratched the surface when it comes to using JSON columns in MySQL.
Whenever you need to save data as key/value pairs in a separate table or work with flexible attributes for an entity, you should consider using a JSON data type field instead as it can heavily contribute to compressing your database design.
If you are interested in diving deeper, the MySQL documentation is a great resource to explore JSON concepts futher.
In this short tutorial I’ll show you how to make permanent redirect from a www URL to non-www and vice versa. I’ll assume that you have superuser privileges, sudo or root access and Nginx already configured, as well as DNS records. More specifically, you need to have an A records for www.yourdomain.com and yourdomain.com .
Redirect non-www to www
To redirect users from a plain, non-www domain to a www domain, you need to add this snippet in your Nginx domain configuration file:
1 2 3 4
server { server_name yourdomain.com return 301 http://www.yourdomain.com$request_uri; }
Save your configuration and exit. Before restarting Nginx make sure to test your configuration:
1
root@secure:~# nginx -t
You should have something like this as output:
1 2 3
root@secure:~# nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful
Now when everything is checked you can restart Nginx:
1
root@secure:~# service nginx restart
Now, if you curl your plain domain, you should get a 301 Moved Permanently response:
In the previous example you saw how to redirect users from a plain non-ww domain to a www domain. However, if you want to redirect from a www to a plain non-www domain you need to add following snippet in your domain configuration file:
1 2 3 4
server { server_name www.yourdomain.com; return 301 $scheme://yourdomain.com$request_uri; }
After any change in Nginx configuration files you should test it for syntax errors:
1 2 3
root@secure:~# nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful
And if you curl the www domain you should get same 301 Moved Permanently response: