Python
Demo:
autopep8
代码格式化:
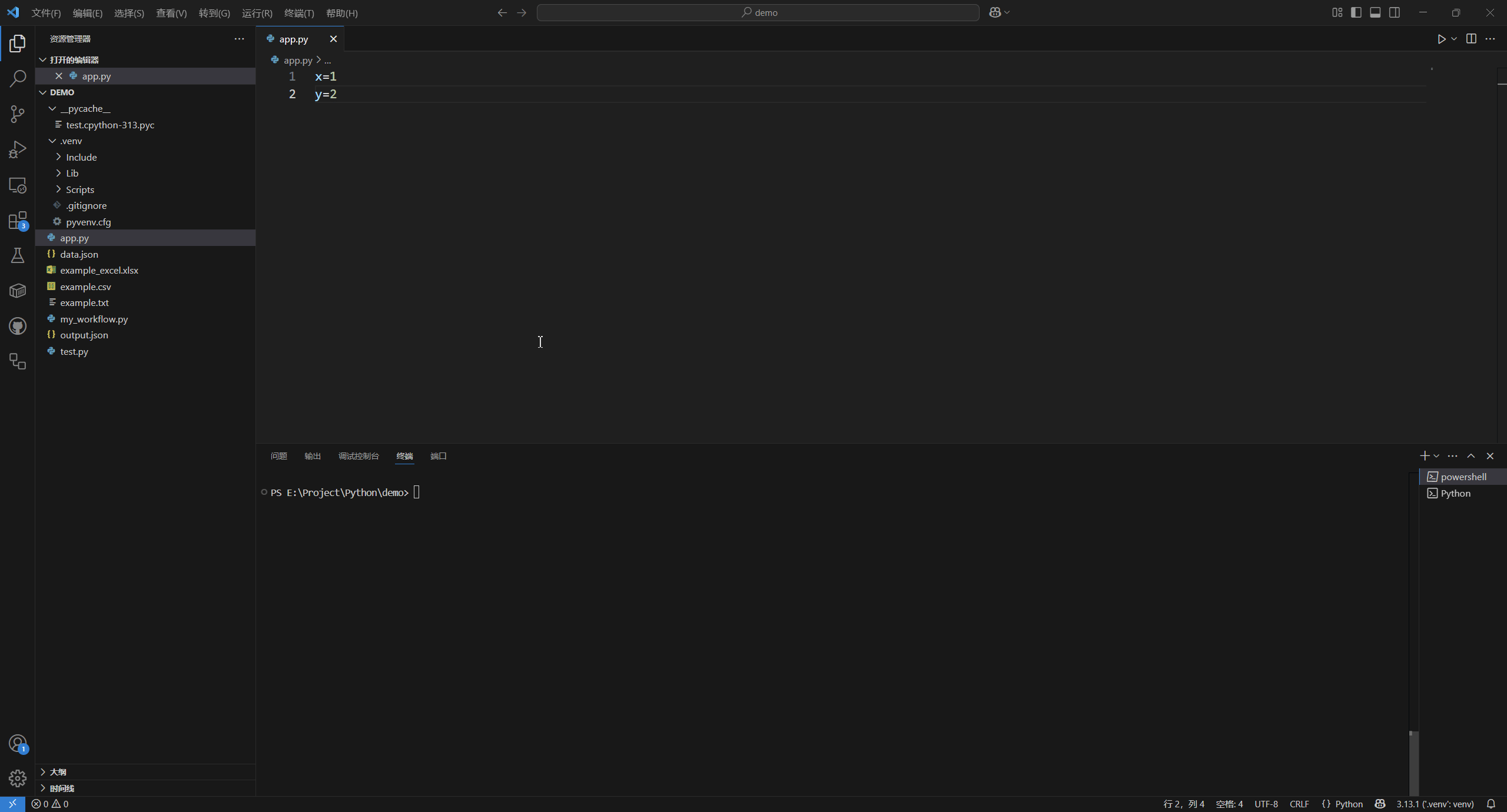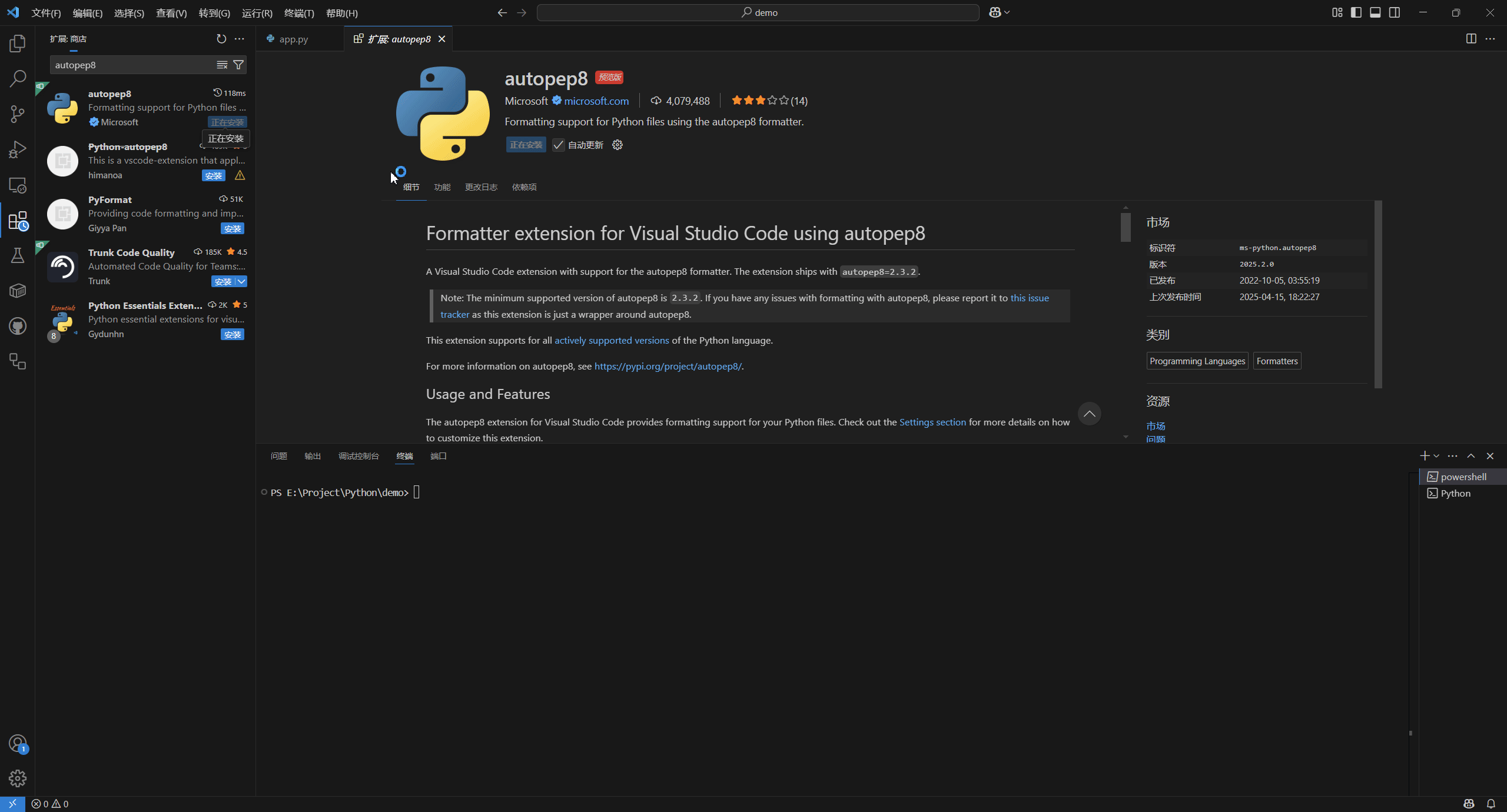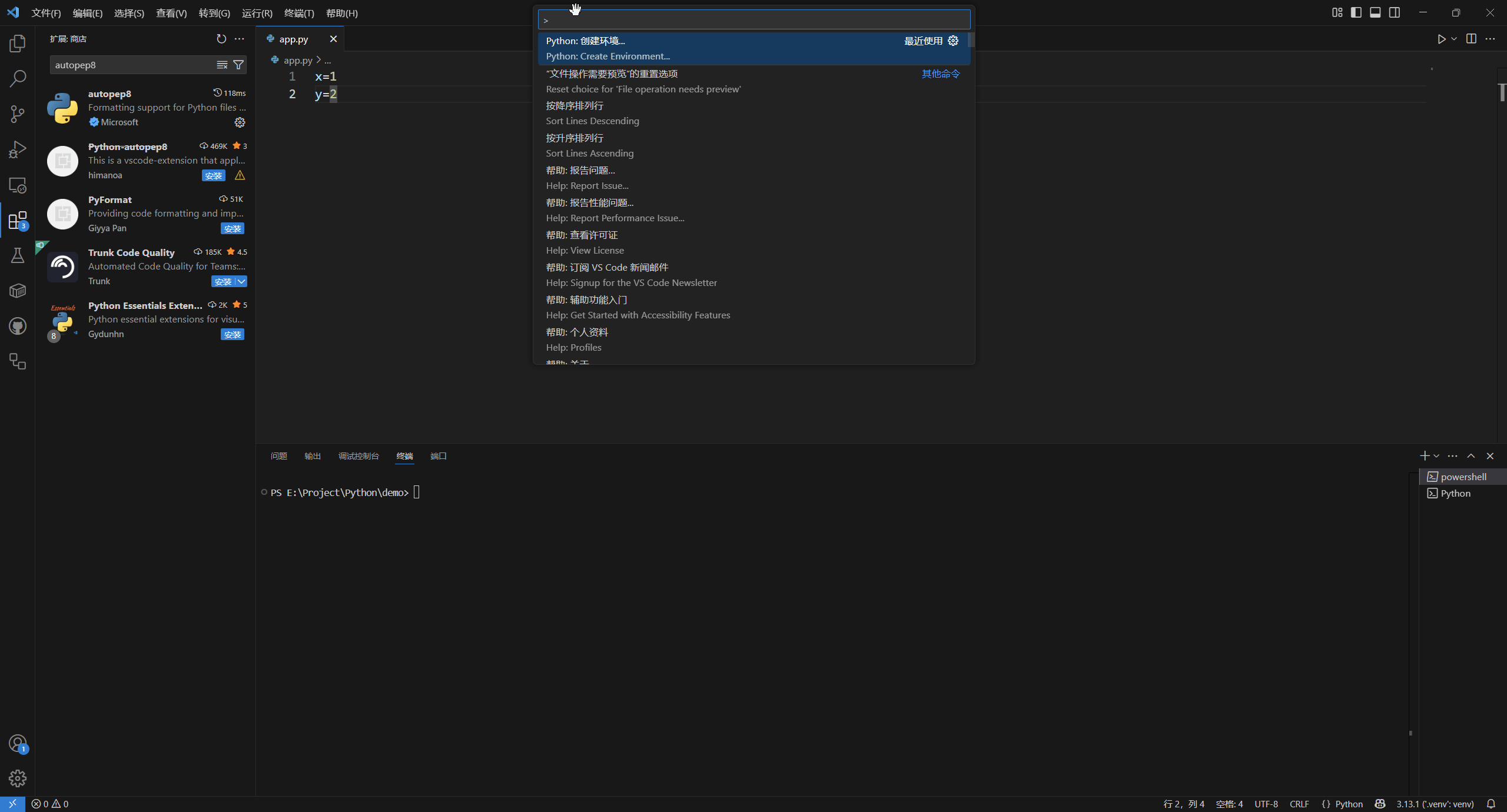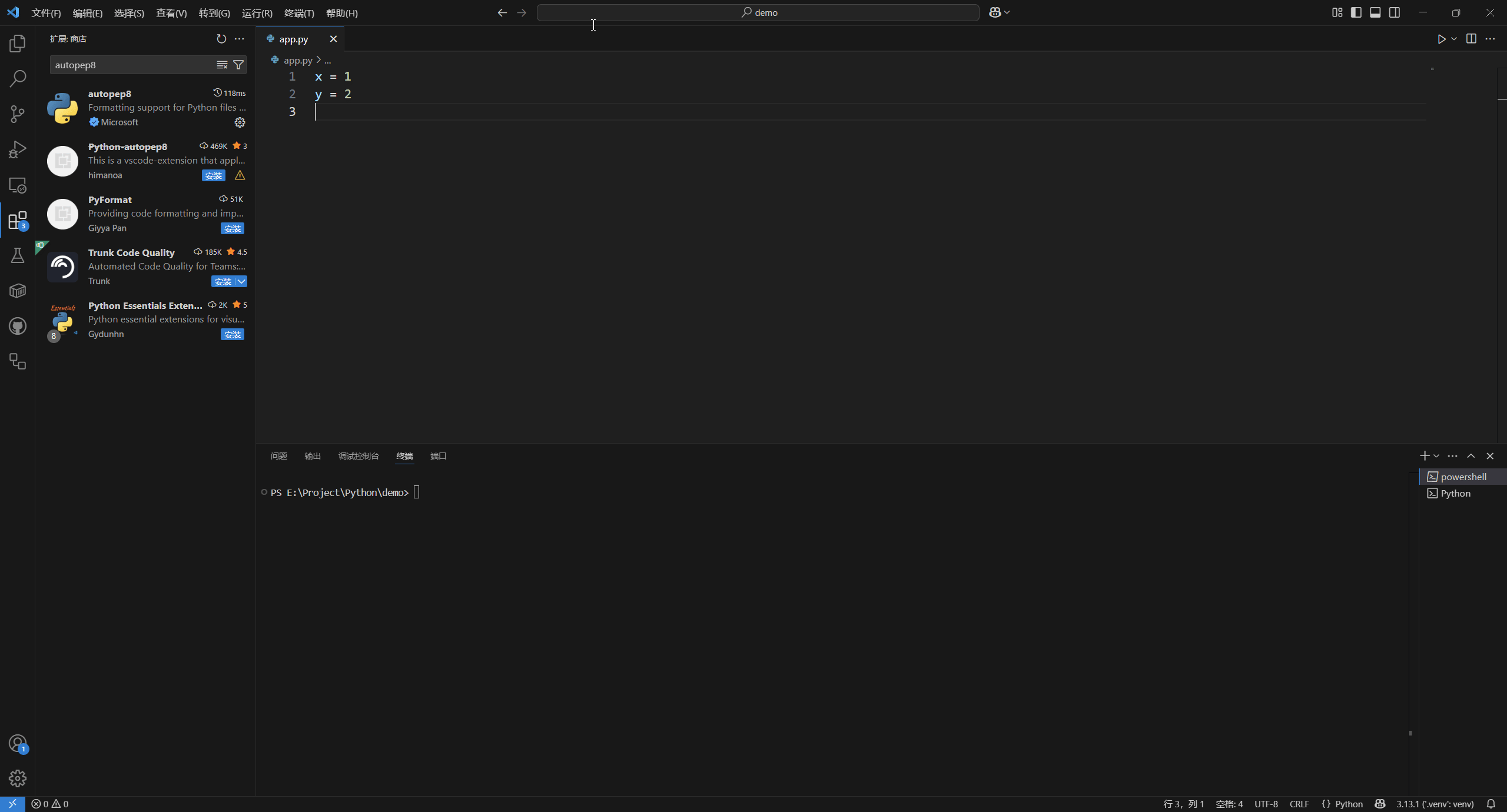
设置保存时自动格式化代码:

“智能体”(Agent)可以有多种定义方式。一些客户将智能体定义为完全自主的系统,能够长时间独立运行,并利用各种工具完成复杂任务。另一些客户则用该术语指代遵循预设流程、更具规范性的实现方式。在 Anthropic,我们将所有这些变体统称为智能体系统(agentic systems),但在架构上对工作流(workflows)和智能体(agents)做出了重要区分:
接下来,我们将详细探讨这两种类型的智能体系统。在附录 1(“智能体实践”)中,我们将具体描述客户在应用此类系统时发现特别有价值的两个领域。
在构建基于大语言模型(LLM)的应用时,我们建议尽可能寻求最简单的解决方案,仅在必要时才增加复杂性。这可能意味着完全不构建智能体系统。智能体系统通常以延迟和成本为代价,来换取更好的任务表现;您需要仔细考量这种取舍在何时是合理的。
当确实需要更高的复杂性时,工作流(Workflows)为定义明确的任务提供了可预测性和一致性;而当需要大规模灵活性和模型驱动的决策时,智能体(Agents)是更好的选择。然而,对于许多应用而言,通过检索(Retrieval)和上下文示例(In-context Examples)来优化单次 LLM 调用通常就足够了。
目前已有许多框架能够简化智能体系统的实现,包括:
这些框架通过简化诸如调用 LLM、定义和解析工具、链式调用等标准的底层任务,使得入门变得容易。然而,它们通常也会引入额外的抽象层,这些抽象层可能掩盖底层的提示词和响应细节,使其更难以调试。此外,当更简单的设置就足够时,这些框架也可能诱使开发者添加不必要的复杂性。
我们建议开发者从直接使用 LLM API 开始:许多模式只需几行代码即可实现。如果确实需要使用框架,请确保理解其底层代码。对框架内部机制的错误假设是客户遇到问题的常见根源。
有关一些示例实现,请参阅我们的开发指南。
在本节中,我们将探讨在生产环境中常见的智能体系统模式。我们将从基础构建单元——增强型LLM(Augmented LLM)——开始,并逐步提升复杂度,从简单的组合式工作流(Compositional Workflows) 到自主智能体(Autonomous Agents)。
智能体系统的基本构建单元是经过增强的大语言模型(LLM),其增强功能包括检索(retrieval)、工具(tools)和记忆(memory)。我们当前的模型能够主动调用这些能力——自主生成搜索查询、选择合适的工具,并决定应留存哪些信息。
![]()
在实现方面,我们建议重点关注两个关键方面:针对您的特定用例定制这些能力,以及确保它们为您的LLM提供一个简单、文档完善的接口。虽然实现这些增强功能的方法多种多样,但其中一种方式是通过我们最近发布的 Model Context Protocol。该协议允许开发者通过简单的客户端实现,与日益增长的第三方工具生态体系进行集成。
在本文的后续部分,我们将默认每次LLM调用都具备这些增强能力。
提示链(Prompt Chaining) 将一个任务分解为一系列步骤,其中每次LLM调用都处理前一次调用的输出。您可以在任何中间步骤添加程序化检查(参见下图中的“门控(gate)”),以确保流程仍在正轨上。
![]()
何时使用此工作流: 此工作流非常适用于任务能够轻松、清晰地分解为固定子任务的情况。其主要目标是以延迟为代价换取更高的准确性,因为每个LLM调用处理的任务都变得更简单。
提示链有用的示例:
路由(Routing) 对输入进行分类,并将其导向专门的后续任务。这种工作流实现了关注点分离(separation of concerns),并允许构建更专业化的提示词。若不采用此工作流,针对某一类输入的优化可能会损害其他输入的处理效果。
![]()
何时使用此工作流: 路由非常适用于处理复杂任务的情况,特别是当任务中存在明显不同的类别(这些类别更适合分开处理),并且分类过程能够准确完成(无论是通过LLM还是更传统的分类模型/算法)时。
路由有用的示例:
大语言模型(LLM)有时可以同时处理一个任务,并通过程序化方式聚合它们的输出。这种工作流,即并行化(Parallelization),主要有两种关键形式:
![]()
何时使用此工作流: 当被划分的子任务可以并行执行以提高速度,或者需要多种视角或多次尝试以获得更高置信度的结果时,并行化非常有效。对于具有多重考量因素的复杂任务,LLM通常在每个考量因素由单独的LLM调用处理时表现更好,这允许模型专注于每个特定的方面。
并行化有用的示例:
分块执行(Sectioning)示例:
投票聚合(Voting)示例:
在协调者-工作者(Orchestrator-Workers)工作流中,一个中央LLM(协调者) 会动态地分解任务,将它们委派给工作者LLMs,并合成它们的结果。
![]()
何时使用此工作流: 此工作流非常适合处理无法预测所需子任务的复杂任务(例如,在编码任务中,需要修改的文件数量以及每个文件的修改性质很可能取决于具体任务)。虽然结构上与并行化(Parallelization)相似,但其关键区别在于灵活性——子任务并非预先定义,而是由协调者根据具体输入动态确定。
协调者-工作者工作流有用的示例:
在评估者-优化者(Evaluator-Optimizer)工作流中,一个LLM调用负责生成响应,而另一个LLM调用则在一个循环中提供评估和反馈。
![]()
何时使用此工作流: 当我们拥有清晰的评估标准,并且迭代优化能带来可衡量的价值时,此工作流特别有效。适用该工作流的两个关键信号是:首先,当人类明确表达反馈时,LLM的响应能够得到显著改进;其次,LLM本身能够提供此类反馈。这类似于人类作者在创作一篇经过润色的文档(polished document) 时可能经历的迭代写作过程。
评估者-优化者工作流有用的示例:
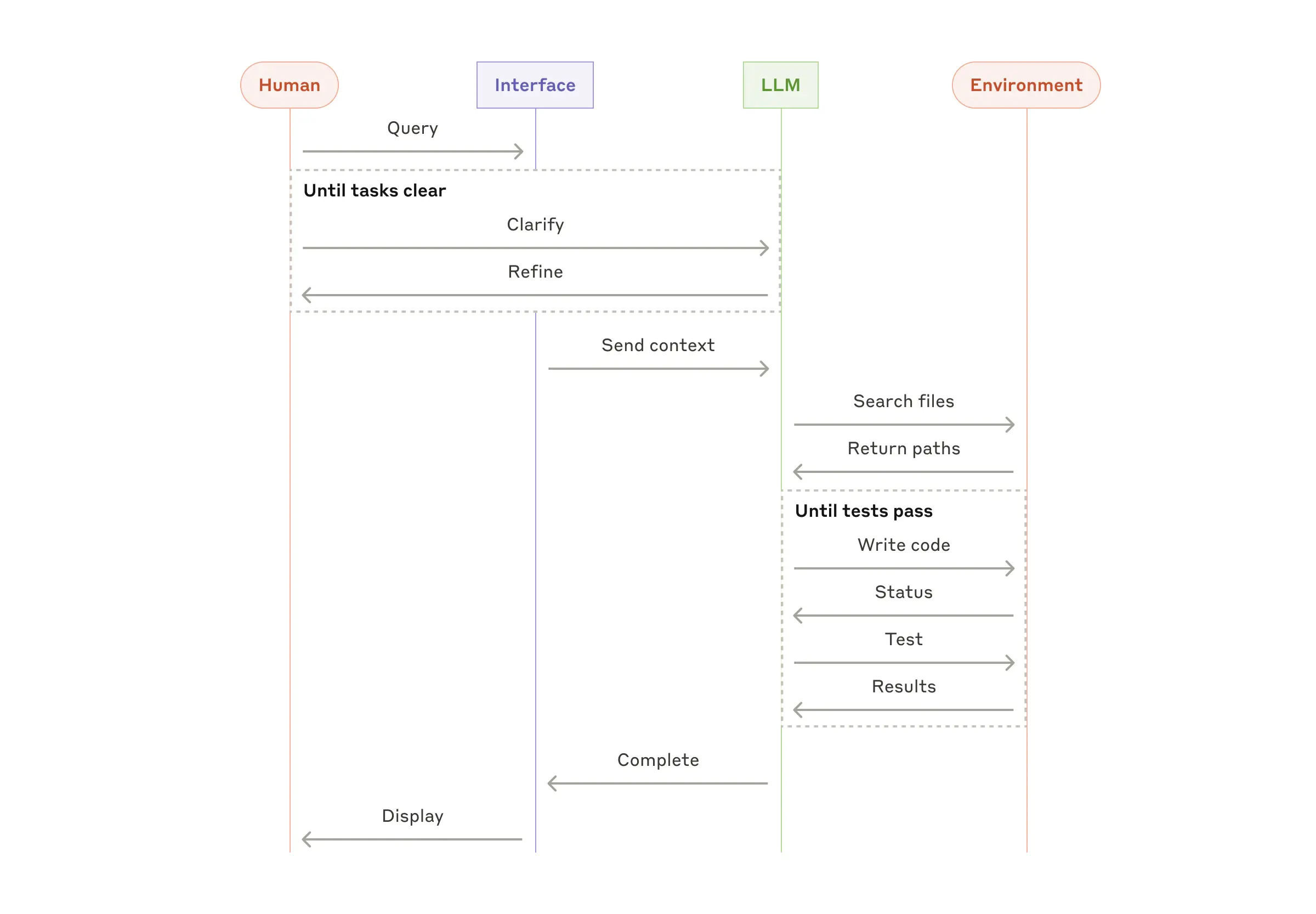
随着大语言模型(LLM)在关键能力上的成熟——包括理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复——智能体(Agents) 正在生产环境中崭露头角。
智能体开始工作时,会接收人类用户的指令或与其进行交互讨论。一旦任务明确,智能体便独立进行规划和操作,并可能在需要时返回人类处寻求更多信息或判断。在执行过程中,智能体在每个步骤都从环境中获取“真实反馈”(ground truth)(例如工具调用结果或代码执行结果)以评估其进展。智能体可以在检查点(checkpoints) 或遇到阻碍(blockers) 时暂停,等待人类反馈。任务通常在完成后终止,但也常会设置停止条件(stopping conditions)(例如最大迭代次数)以保持控制。
智能体能够处理复杂的任务,但其实现通常很直接。它们通常只是一个循环运行的LLM,基于环境反馈使用工具。因此,清晰且深思熟虑地设计工具集及其文档至关重要。我们在附录 2(“工具提示词工程(Prompt Engineering your Tools)”)中详细阐述了工具开发的最佳实践。
![]()
何时使用智能体: 智能体适用于处理开放式问题(open-ended problems),这类问题的所需步骤数量难以或无法预测,并且无法硬编码固定路径。LLM可能需要运行多个轮次,因此您必须对其决策能力有一定程度的信任。智能体的自主性(autonomy) 使其成为在受信任环境中扩展任务的理想选择。
智能体的自主特性也意味着更高的成本和错误累积(compounding errors) 的可能性。我们建议在沙盒环境(sandboxed environments) 中进行广泛的测试,并设置适当的防护机制(guardrails)。
智能体有用的示例:
以下示例来自我们自己的实现:
这些构建单元(building blocks) 并非规定性的(prescriptive)。它们是开发者可以塑造(shape)和组合(combine) 以适应不同用例的常见模式(common patterns)。与任何LLM功能一样,成功的关键在于衡量性能(measuring performance)并对实现进行迭代(iterating on implementations)。再次强调:仅当能够显著改善结果时,您才应考虑增加复杂性。
在LLM领域取得成功,不在于构建最复杂的系统,而在于构建适合您需求的正确系统。从简单的提示词开始,通过全面评估(comprehensive evaluation) 对其进行优化,仅当更简单的解决方案无法满足需求时,才添加多步骤的智能体系统。
在实现智能体时,我们力求遵循三个核心原则:
框架可以帮助您快速入门,但在进入生产环境时,请毫不犹豫地减少(甚至移除)抽象层,并使用基础组件进行构建。遵循这些原则,您可以创建出不仅强大,而且可靠、易维护且值得用户信赖的智能体。
我们与客户合作的经验揭示了两种特别有前景的AI智能体应用,它们展示了上述模式的实际价值。这两种应用都说明了智能体在哪些任务中能发挥最大价值:需要对话与行动相结合、具有清晰的成功标准、支持反馈循环、并整合了有意义的人工监督的任务。
A. 客户支持(Customer support)
客户支持将熟悉的聊天机器人界面与通过工具集成实现的增强功能相结合。这自然更适合开放式智能体,因为:
多家公司已通过按成功解决量计费(usage-based pricing models) 的模式证明了这种方法的可行性,这显示了他们对其智能体有效性的信心。
B. 编码智能体(Coding agents)
软件开发领域在利用LLM功能方面展现出显著潜力,其能力已从代码补全发展到自主解决问题。智能体在此特别有效,因为:
在我们自己的实现中,智能体现在仅基于拉取请求(pull request)描述,就能在 SWE-bench Verified 基准测试中解决真实的 GitHub issues(问题)。然而,虽然自动化测试有助于验证功能,但人工审查对于确保解决方案符合更广泛的系统要求仍然至关重要。
无论您构建哪种智能体系统,工具(tools) 都可能是您智能体的重要组成部分。工具使 Claude 能够通过在我们的 API 中精确指定其结构和定义来与外部服务和 API 交互。当 Claude 响应时,如果它计划调用工具,它将在 API 响应中包含一个 tool_use 块。工具定义和规范的提示词工程应与您的整体提示词受到同等重视。在这个简短的附录中,我们将描述如何对您的工具进行提示词工程。
通常有多种方法可以指定相同的操作。例如,您可以通过编写差异(diff) 或重写整个文件来指定文件编辑。对于结构化输出,您可以在 Markdown 中或 JSON 内部返回代码。在软件工程中,这些差异是表面性的,可以无损地从一种格式转换为另一种格式。然而,某些格式对于 LLM 来说比其他格式更难编写:
我们关于决定工具格式的建议如下:
一个经验法则是:思考投入在人类-计算机交互界面(HCI) 上的工作量,并计划投入同样多的精力来创建良好的智能体-计算机接口(ACI)。以下是一些关于如何做到这一点的想法:
在构建用于 SWE-bench 的智能体时,我们实际上在优化工具上花费的时间比优化整体提示词还要多。例如,我们发现当智能体移出根目录后,模型在使用涉及相对文件路径(relative filepaths) 的工具时会出错。为了解决这个问题,我们将工具更改为始终要求绝对文件路径(absolute filepaths)——结果发现模型能够完美地使用这种方法。
参考:
Laravel 的 loadMissing 方法提供了一种灵活的方式,对现有模型或集合进行预加载。该方式避免了 N+1 的查询问题,同时允许你只在需要时加载关联。
当使用可选的内容或仪表板构建 API 时,此功能尤其有价值,因为不同的部分需要不同的关联数据。
1 | $post->loadMissing(['comments', 'author']); |
以下是仪表盘数据加载器的示例:
1 |
|
loadMissing 方法智能地仅加载所需的关联:
1 | // GET /dashboard/1?section=analytics |
LoadMissing 提供了一个有效的方式来管理管理加载、优化数据库查询,同时保留了代码的灵活性。
Laravel 的 named 方法提供了一种干净的方法来确定当前请求是否与特定路由名称匹配。这个强大的功能允许你根据当前路由执行条件逻辑,非常适合分析、导航突出显示或权限检查。
当构建需要根据当前路由表现不同的组件时,这种方法变得特别有价值,而无需在整个应用中编写重复的条件检查。
1 | if ($request->route()->named('dashboard')) { |
以下是实现动态导航状态的实例:
1 |
|
在应用中使用时,该导航组件自动检测当前路由并进行相应的更新:
1 |
|
named 方法简化了基于路由的逻辑,使得代码更具可维护性,并减少路由依赖的复杂性。
轻松创建应用程序的指标。(Easily create metrics for your application.)
https://github.com/sakanjo/laravel-easy-metrics
Bar metricDoughnut metricLine metricPie metricPolar metricTrend metricValue metric1 | composer require sakanjo/laravel-easy-metrics |
1 | use SaKanjo\EasyMetrics\Metrics\Value; |
The currently supported aggregate functions to calculate a given column compared to the previous time interval / range
1 | Value::make(User::class) |
1 | Value::make(User::class) |
1 | Value::make(User::class) |
1 | Value::make(User::class) |
1 | Value::make(User::class) |
1 | use SaKanjo\EasyMetrics\Metrics\Doughnut; |
It’s always better to use the
optionsmethod even though it’s optional, since the retrieved data may not include all enum options.
The currently supported aggregate functions to calculate a given column compared to the previous time interval / range
1 | Doughnut::make(User::class) |
1 | Doughnut::make(User::class) |
1 | Doughnut::make(User::class) |
1 | Doughnut::make(User::class) |
1 | Doughnut::make(User::class) |
1 | use SaKanjo\EasyMetrics\Metrics\Trend; |
The currently supported aggregate functions to calculate a given column compared to the previous time interval / range
1 | $trend->minByYears('age'); |
1 | $trend->maxByYears('age'); |
1 | $trend->sumByYears('age'); |
1 | $trend->averageByYears('age'); |
1 | $trend->countByYears(); |
Bar extends TrendLine extends TrendDoughnut extends PiePolar extends PieEvery metric class contains a ranges method, that will determine the range of the results based on it’s date column.
1 | use SaKanjo\EasyMetrics\Metrics\Trend; |
Range::TODAYRange::YESTERDAYRange::MTDRange::QTDRange::YTDRange::ALL1 |
|
在 https://github.com/hefengbao/hefengbao.github.io 仓库使用 vitepress 建立站点,部署到 Github Page 后,访问 https://hefengbao.github.io 不能加载样式,,因为使用 vitepress 建立过 https://hefengbao.github.io/knowledge 等站点,所以配置是没问题的,做了一些测试,发现无法加载 assets 目录下的文件,然而 https://hefengbao.github.io/knowledge 站点下却是没问题的😓。

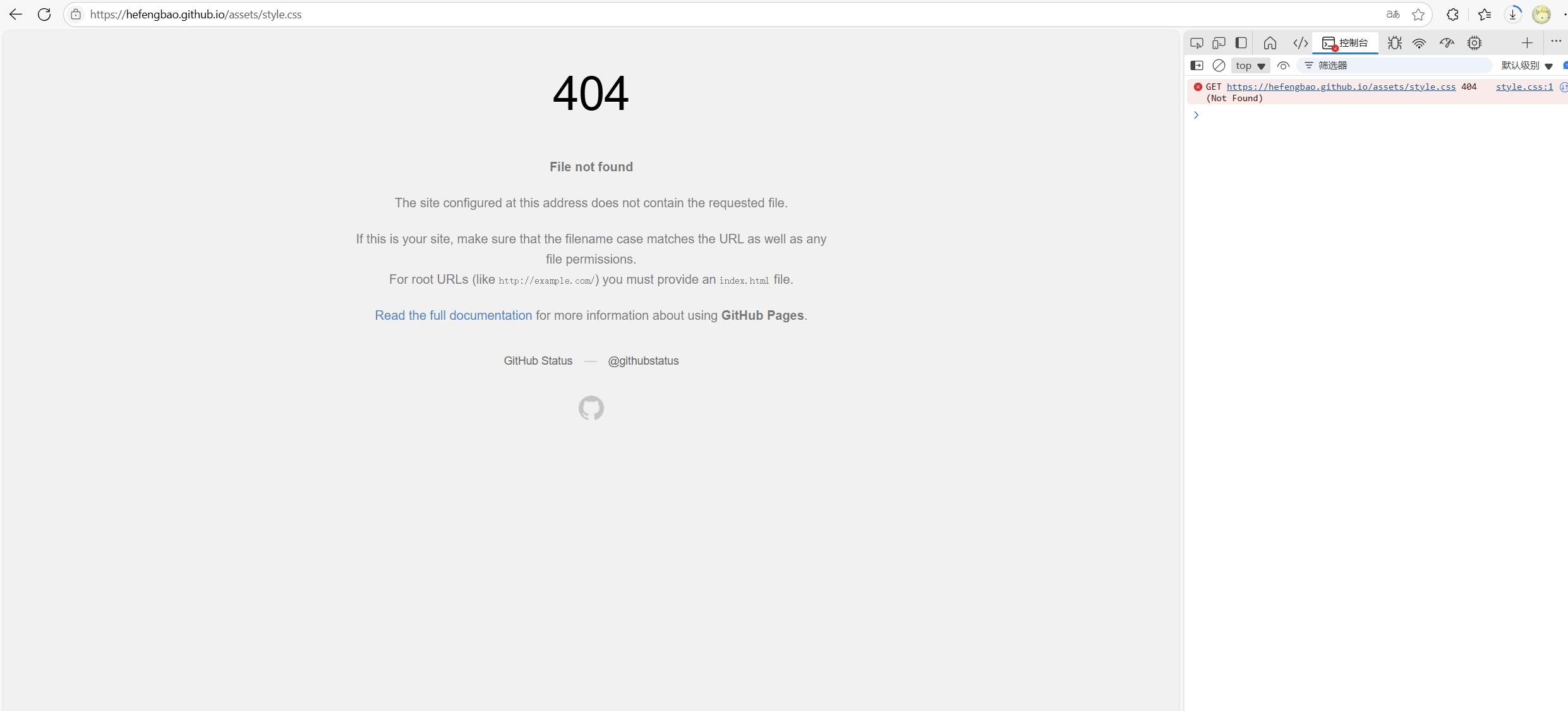
于是想有没有办法修改打包后静态资源输出的目录名称,查找 vitepress 的文档,果然可以设置:https://vitepress.dev/zh/reference/site-config#assetsdir。
1 | export default { |
官方下载 Node.js — Download Node.js®
可以自定义安装路径,比如我安装在 E:\Program\nodejs 目录下,其他点“下一步/Next” 即可。
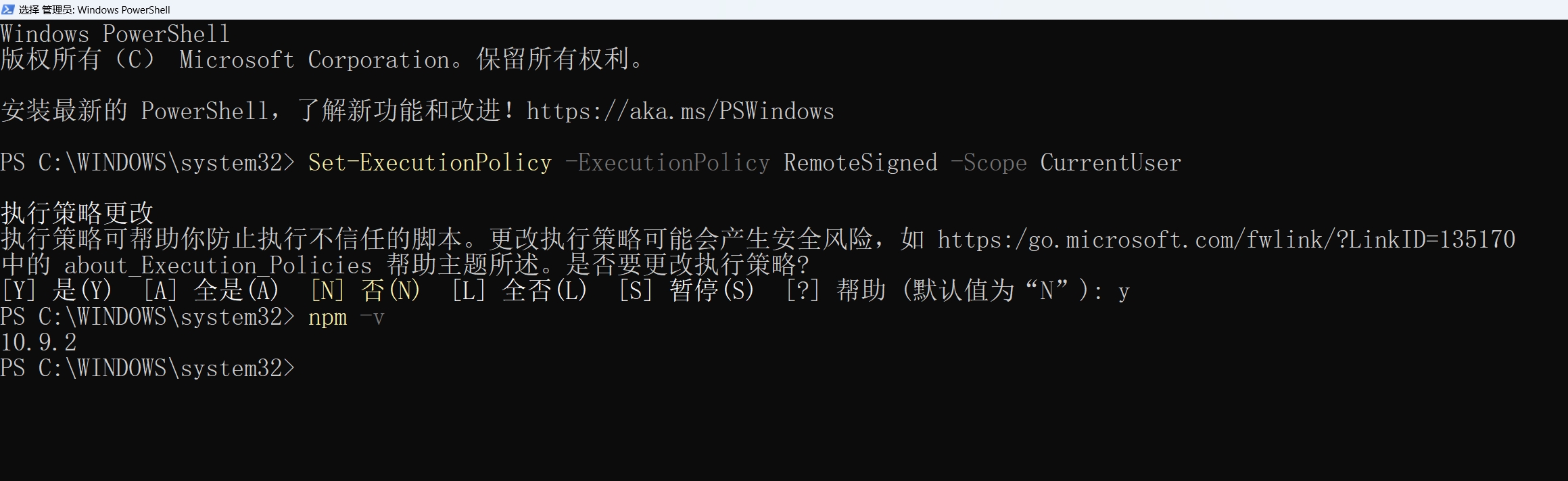
运行 npm -v 出错😓:
1 | PS C:\Users\OoO> npm -v |
解决:
请使用 以管理员身份运行 选项启动 PowerShell,运行如下命令🔗:
1 | Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser |
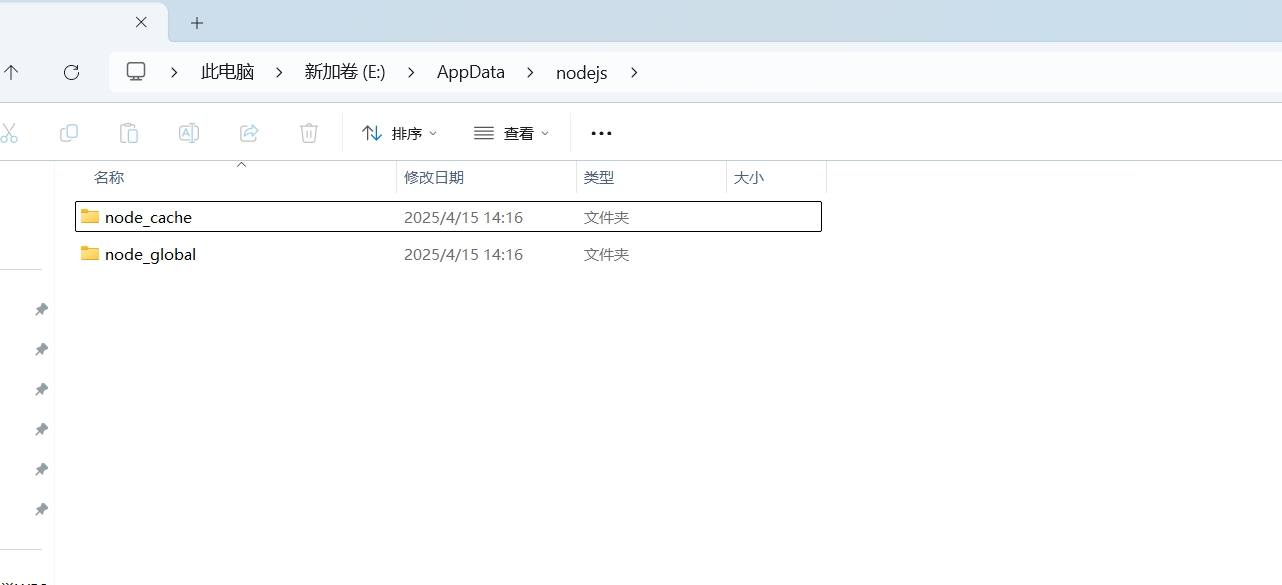
npm config get prefix 命令查看全局依赖(inpm insall -g xx)安装位置,npm config get cache 查看 npm 缓存位置,可以看出都在 C 盘目录下。
1 | PS C:\WINDOWS\system32> npm config get prefix |
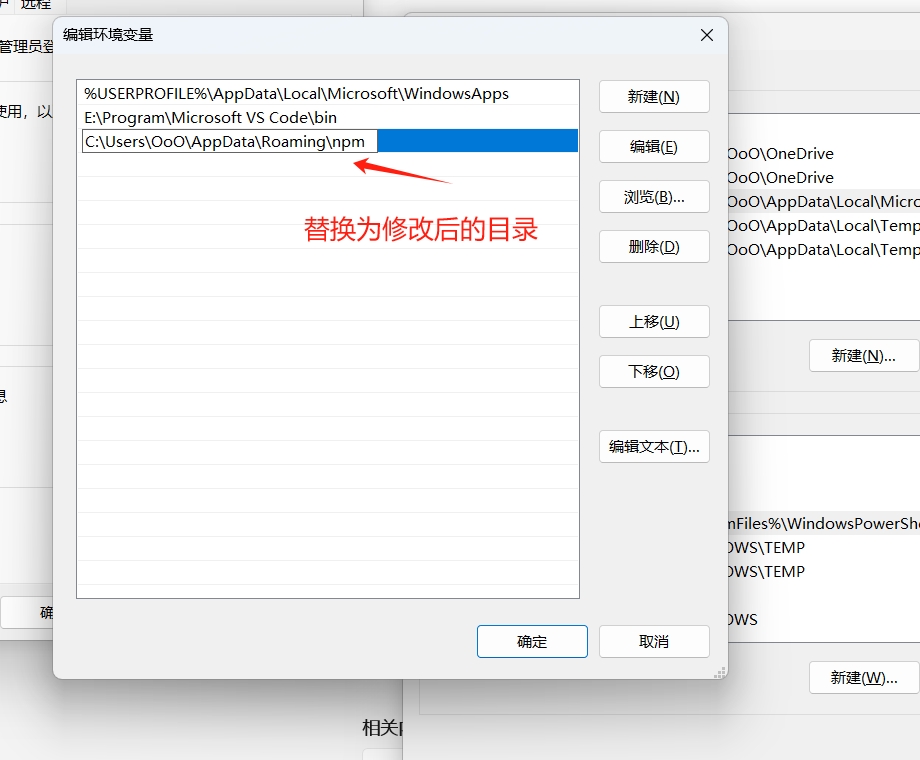
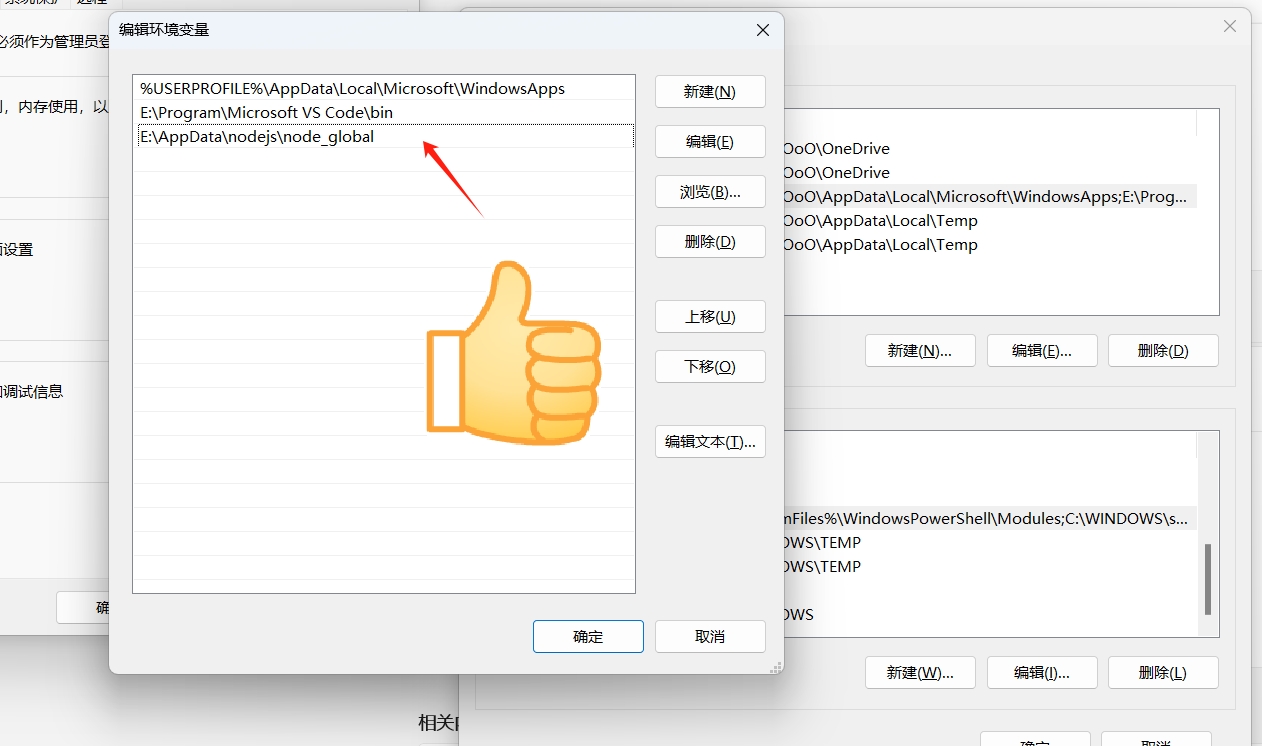
如果 C 盘空间小,可以修改到其他盘。我的目录 E:\AppData\nodejs:
通过如下命令修改目录:
1 | npm config set cache "E:\AppData\nodejs\node_cache" |
1 | npm config set prefix "E:\AppData\nodejs\node_global" |
保存在C:\Users\{用户名} 目录下的 .npmrc 文件:
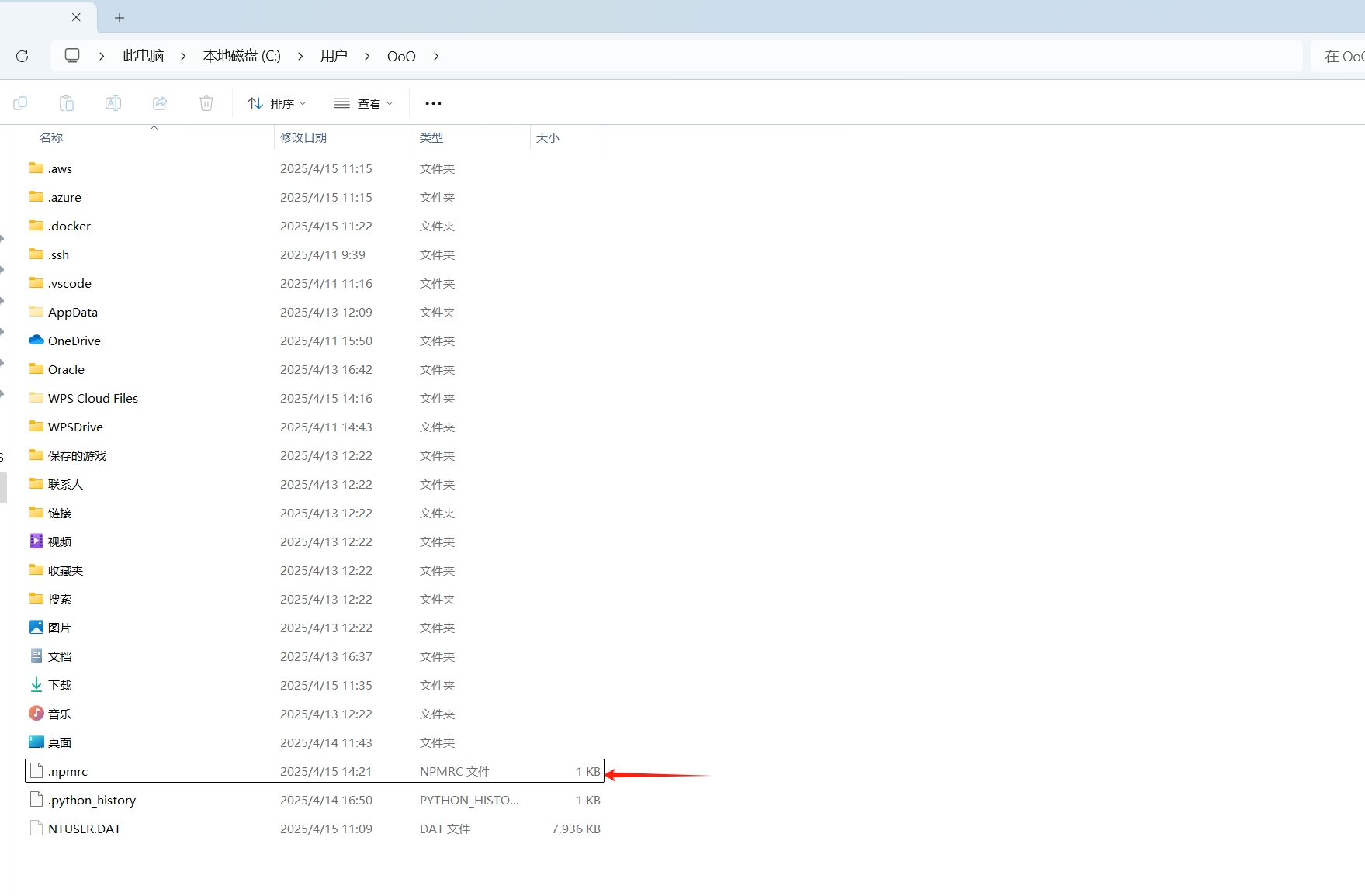
查看 .npmrc 文件:
1 | cache=E:\AppData\nodejs\node_cache |
修改环境变量,以下打开“环境变量”是基于 Windows 11 演示:
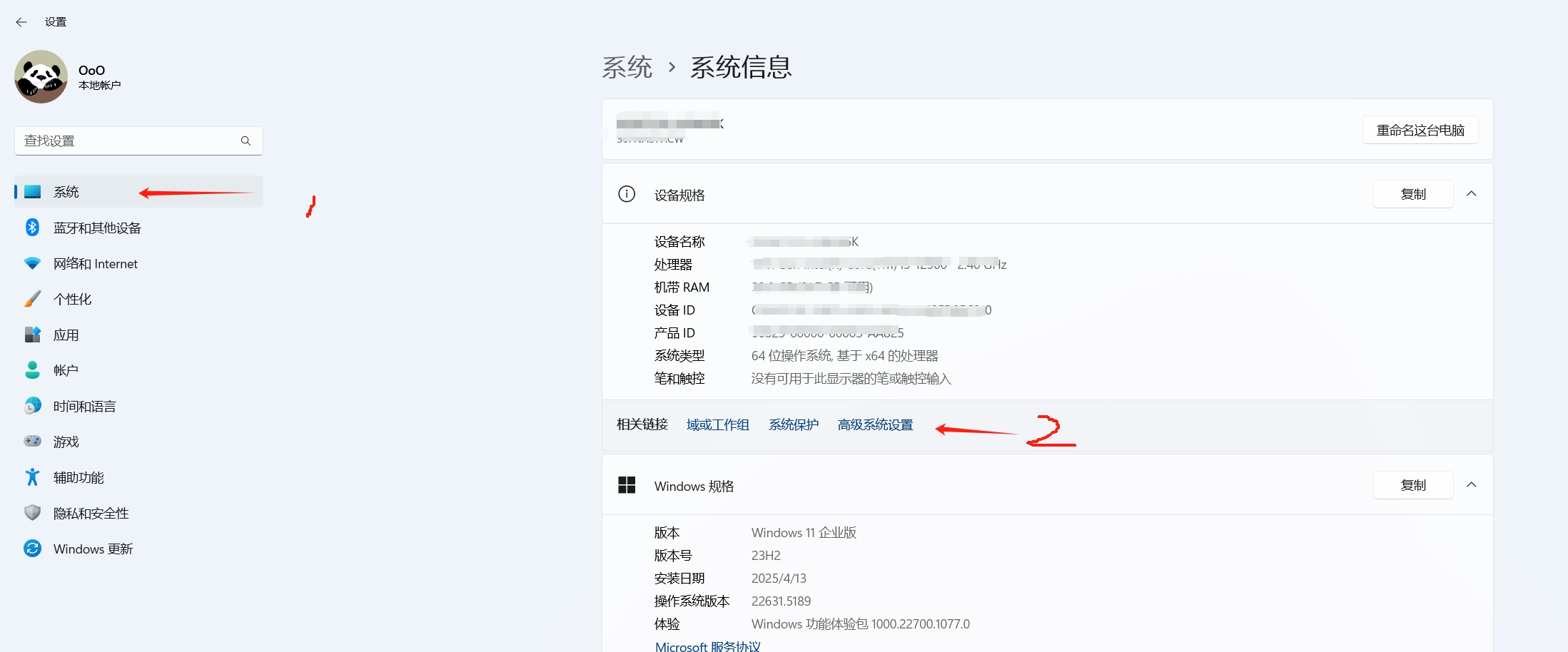

1 |
|
1 | $stream = Http::throw() |
参考:
https://yellowduck.be/posts/using-streaming-http-responses-in-laravel
官方也有实现😓
https://laravel.com/docs/12.x/responses#streamed-json-responses
Windows 系统安装 Android Studio 后,.gradle 用来保存下载的 Gradle 依赖的包,.android 用来保存模拟器,都比较占地方。默认位置为 C:\Users\<用户名>\.gradle 、C:\Users\<用户名>\.android ,如果 C 盘空间不够用,可考虑把这两个目录移到其他盘。首先把这两个目录移到其他盘,我这里移到了 D:\Program\AndroidDev 目录下。
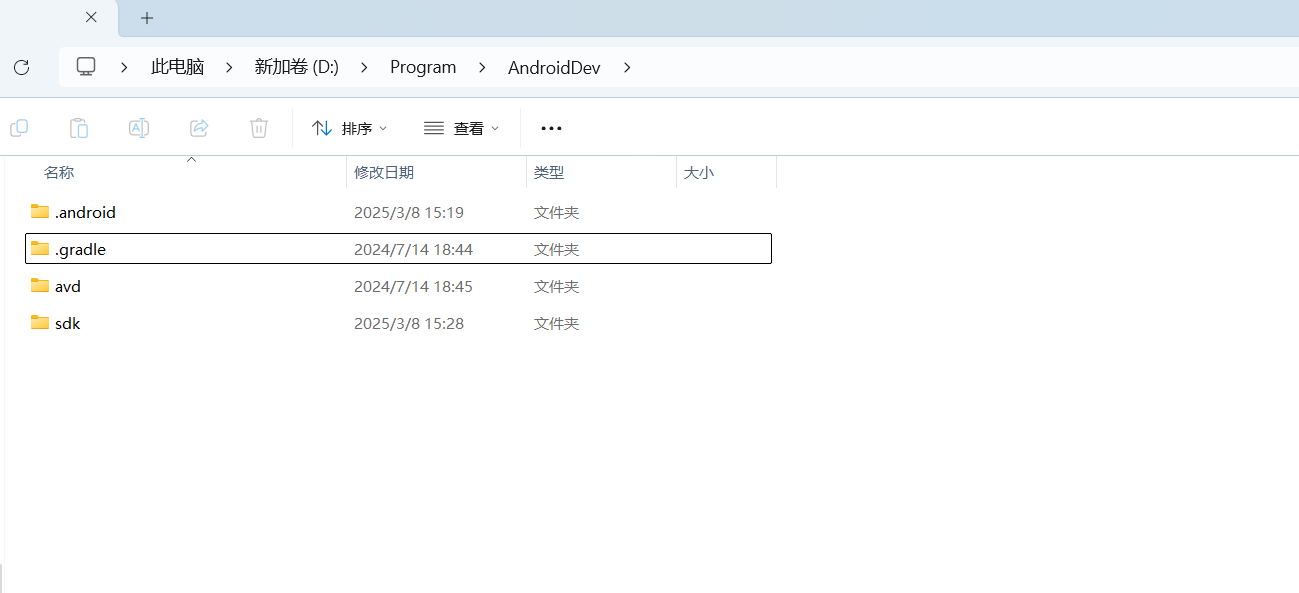
添加环境变量,.gradle 需要添加的是 GRADLE_USER_HOME :
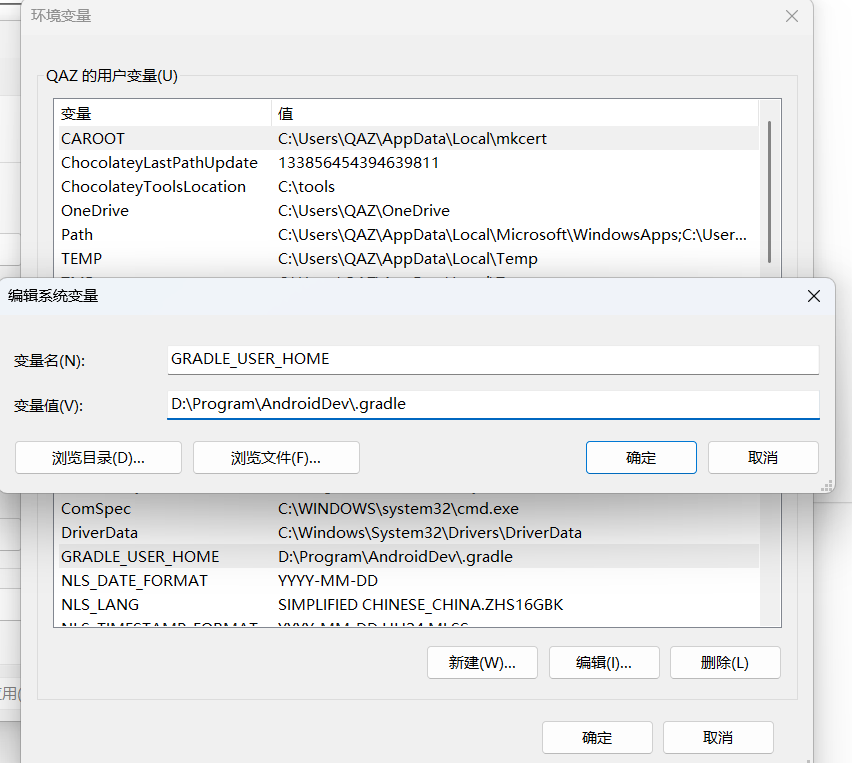
.android 需要添加的是 ANDROID_SDK_HOME :
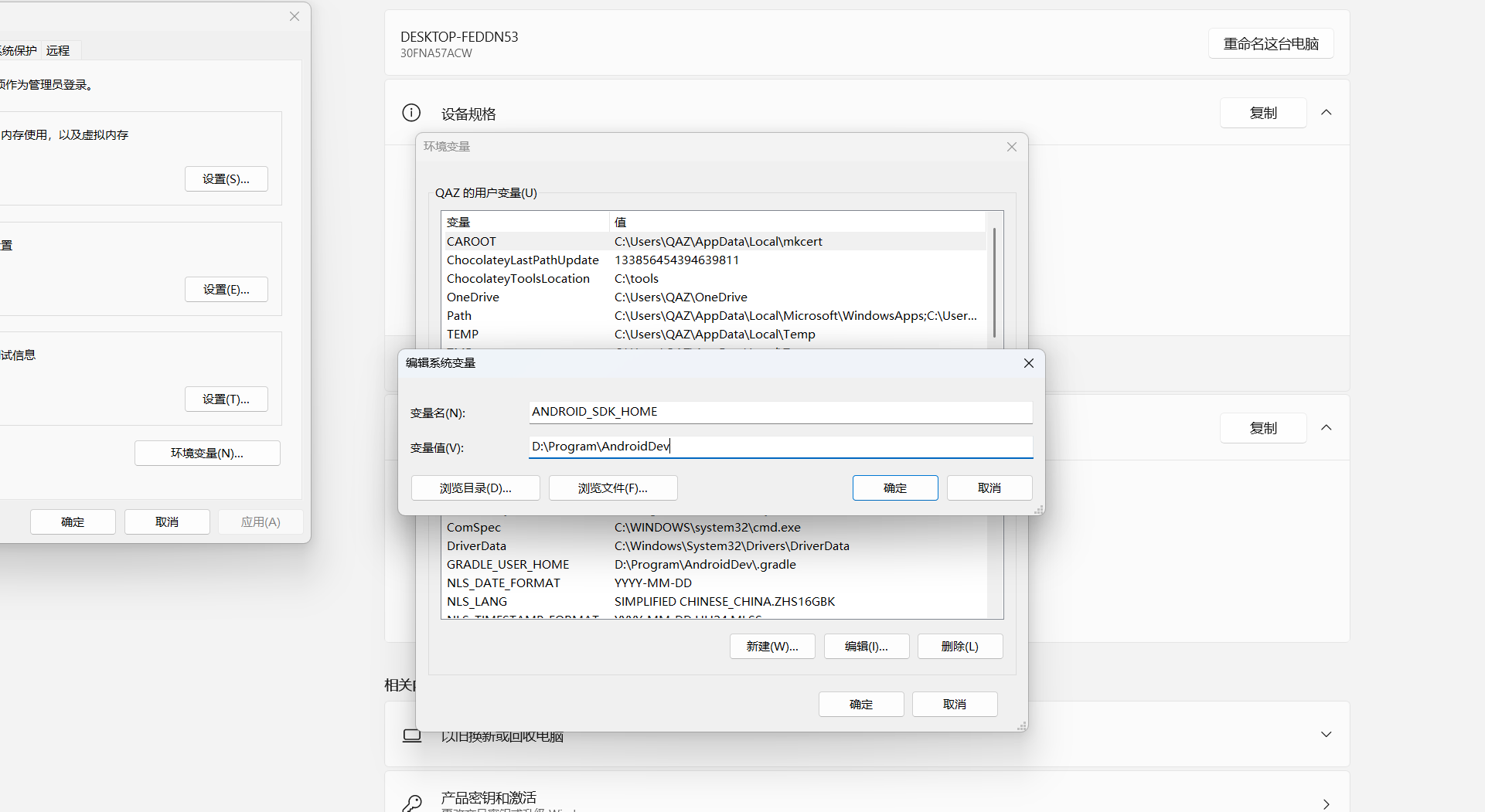
1 | sudo docker pull nginx |
1 | sudo docker run -d -p 80:80 --name my-nginx-server nginx |
-d: 以分离模式启动容器(容器在后台运行)。
-p: 绑定容器到主机的端口(将主机 8 0端口的请求导到容器的 80 端口)。
-name: Docker 容器的名字(实例中是my-nginx-server)
现在可以打开浏览器,使用本机 IP 访问:如 http://127.0.0.1。应该能看到 Nginx 的默认页面。
1 | sudo docker container ls |
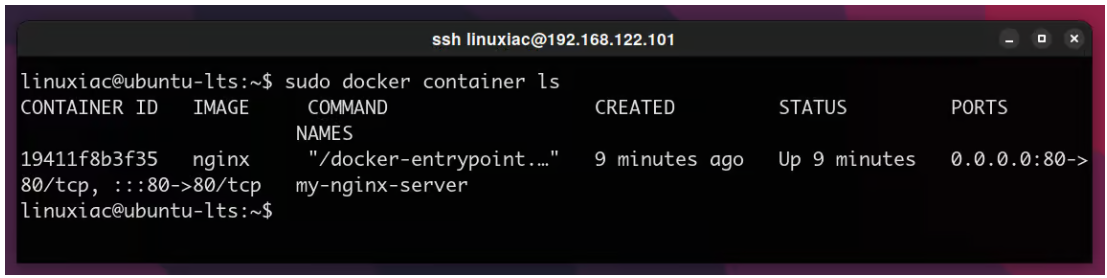
根据上图中的输出,可以使用两种方法停止 Nginx 的 Docker 容器:
1 | sudo docker stop 19411f8b3f35 |
查看所有的容器,包含未运行的,需要使用 -a 参数:
1 | sudo docker container ls -a |
默认情况下,在容器内创建的任何数据只能在容器内使用,并且只能在容器运行时使用。但是容器可能被销毁,所以接下来要做的是让容器使用保存在主机中的数据。为了实现这一功能,我们将使用Docker中的绑定挂载功能。当您使用绑定挂载时,主机上的文件或目录会被挂载到容器中。
1 | mkdir ~/www |
1 | vim ~/www/index.html |
复制粘贴如下示例内容
1 | <html> |
接下来,我们将运行Nginx Docker容器,并将容器 /usr/share/nginx/html 的目录映射到保存index.html文件的主机www目录上。
1 | docker run -d -p 80:80 -v ~/www:/usr/share/nginx/html/ --name my-nginx-server nginx |
Nginx 容器默认使用的文件目录是 /usr/share/nginx/html/,使用 -v 参数绑定 /usr/share/nginx/html/ 目录到主机的 ~/www 目录。
Docker使用冒号符号(:)将主机路径与容器路径分开。记住,主机路径总是第一位的。